Usually, upstream updates are really well tested and can be considered trusted, but 2 times in 6 NethServer releases, an upstream update broke a NethServer functionality.
During the NethServer Conference, we discussed about this issue during an awesome round table: many ideas came up and I would like to share with anyone and gather more feedback.
The goal is to have clearer (maybe newer) update policy for NethServer 7.4.
We identified some main goals.
Even if upstream updates can be trusted, It’s better to test packages twice if they can impact end users: two test phases are better than one
The responsibility of updates release should be shared among the community
We need to identify a list of well known hot points to check on every minor release (example: shared folder authentication, web proxy, etc)
We also proposed a couple of solutions.
(Short term) The administrator should be able to choose the upgrade policy of its own server:
fast: receive all updates as soon as possible; useful for environment where security is most important like firewalls - This should be the default configuration
slow: receive updates after a grace time period (maybe a couple of weeks); during this time the QA team will do more tests and can block update release if an issue has been found
(Long term) Create automated tests for a selected set of hot points
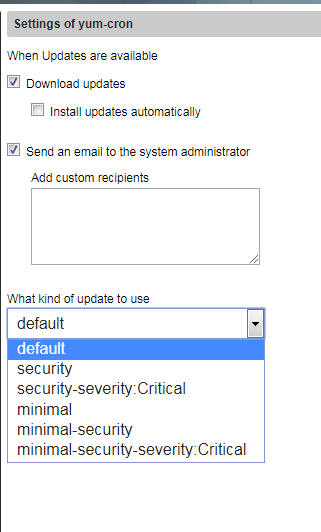
(Short term, an idea that came out this morning by Davide) Include @stephdl yum-cron module inside the core and add there the option to enable the fast or slow updates
Hello,
I think giving administrators the choice could be the right way.
A lot of them will have a second platform to test things. For this server I would choose the fast updates and for the productivity system i would take the slow updates.
The advantage for the devolopers of nethserver is that their could be much more testers for updates.
The only problem I see is, at a productivity system I would choose not to install updates as fast as possible, but what is about security updates?
OS updates from RedHat/CentOS: not tested by the NS Developers and/or by the NS Community; optionally selectable with checkbox.
Product updates from Nethesis and/or NS Contributors for NethServer: already tested by the NS Developers, NS Contributors, NS Community; could be fast; optionally selectable with checkbox.
Security updates should always be pushed as soon as possible on all production servers.
We have all internal machines updated every night from upstream
@giacomo,
Sorry but I think that you may have misunderstood my question, when I was asking about existing documentation and policies, I was specifically referring to existing NS based procedures.
Whilst I understand NS is based on CentOS and the fact that CentOS is based upon RHEL, would it not be sensible to provide our own documented interpretation of these polices.
Whilst I do not wish to appear to be rude or discourteous, is it not a bit of a lazy cop-out and overly bureaucratic to suggest that developers and repository administrators should refer to a load of decentralised documents (written by non NS members) for these important policies?
@Stefano_Zamboni,
I understand that we do not need “reinvent the wheel” or to make any major alterations to any existing documentation but do think that there needs to be some form of policy / procedures easily available to the community.
I am afraid to say that the attitude that is being expressed by yourself reminds me of similar attitudes expressed by British civil servants / public servants (ie. “it is not my responsibility to provide this information and you must trail through a number of documents before you are provided with the relevant information”).
Also, I do consider that using “business speak” / poorly formed acronyms such as “the KISS philosophy” demonstrates a level of indifference and a form of lazy thought process.
We are here not only to provide a product (in the form of the NethServer infrastructure / framework) but also to support and aid the community, and not to act like a load of bureaucratic, imbecilic “jobworths” (no offence intended).
well… we already have NS’ specific documentation about NS’ unique features…
NS heavily depends on upstream… for all the topics where NS adheres to upstream there’s no reason to rewrite any documentation, because:
it’s an evident loss of time/resources/energies
it must be kept uptodate
so, using again the KISS acronym (which, for example, is a must for @stephdl, me and any other linux sysadmin since ages), we have to:
give good reference to upstream official documentation to the community
write good documentation about the features/approaches/solutions adopted in NS which are different from upstream
this will survive to any major release and are easily managed
time is money, and I don’t like to throw it away
and you can have different update-levels, install or download only, send mails…
It covers my needs.
I don’t think so in community environment. Here no one should be moneydriven.
@medworthy
We can only try to improve processes, but we never can be 100% save not to hit a bug with an update.
Normally we do not want to touch running system, but we do need to install updates because of security reasons. So this is a dilemma.
maybe you misunderstood me… my time, your time, everyone’s time is valuable… if we have to invest it on the product, we’d rellay invest in something that is new, unique, not just rewriting something someone else already did.
I’d prefer to spend 2 hours a week to test and debug something new, instead of copy and paste Centos’ documentation to document something useless (already existant)