Using proxmox zfs raid 10. I’m still testing. TLDR: seems like MariaDB is causing problems to shutdown NS VM on Proxmox:
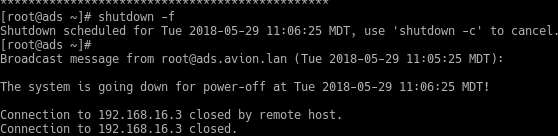
After 3 days running I shutdown the VM (shutdown -f) from a console.
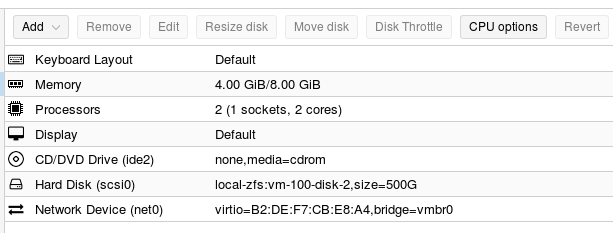
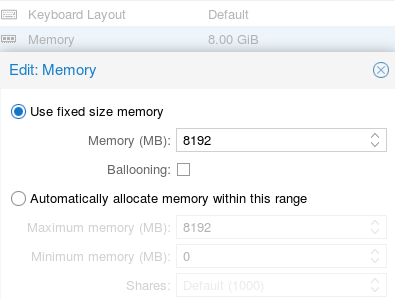
Note#1, With the VM is off, I change the RAM size from 4GB to 8GB as:
Reboot proxmox
The VM is setting up to auto start in proxmox
After reboot, I ping the VM but it only shows 2 pings and stops
From 192.168.21.22 icmp_seq=118 Destination Host Unreachable
(rebooting proxmox)…
64 bytes from 192.168.16.1: icmp_seq=119 ttl=64 time=55.3 ms
64 bytes from 192.168.16.1: icmp_seq=120 ttl=64 time=0.262 ms
^C (interrupted after all stabilized)
I try to check the dashboard, nothing loads
From Proxmox, I can the VM using a console
From my PC I cannot access the VM using ssh
Next steps:
reboot the VM from the console (proxmox)
The reboot was fast, the console shows fine
The dashboard is up and accessible.
Retrying the same steps to see if the phenoms occurs again.
Shutdown the VM
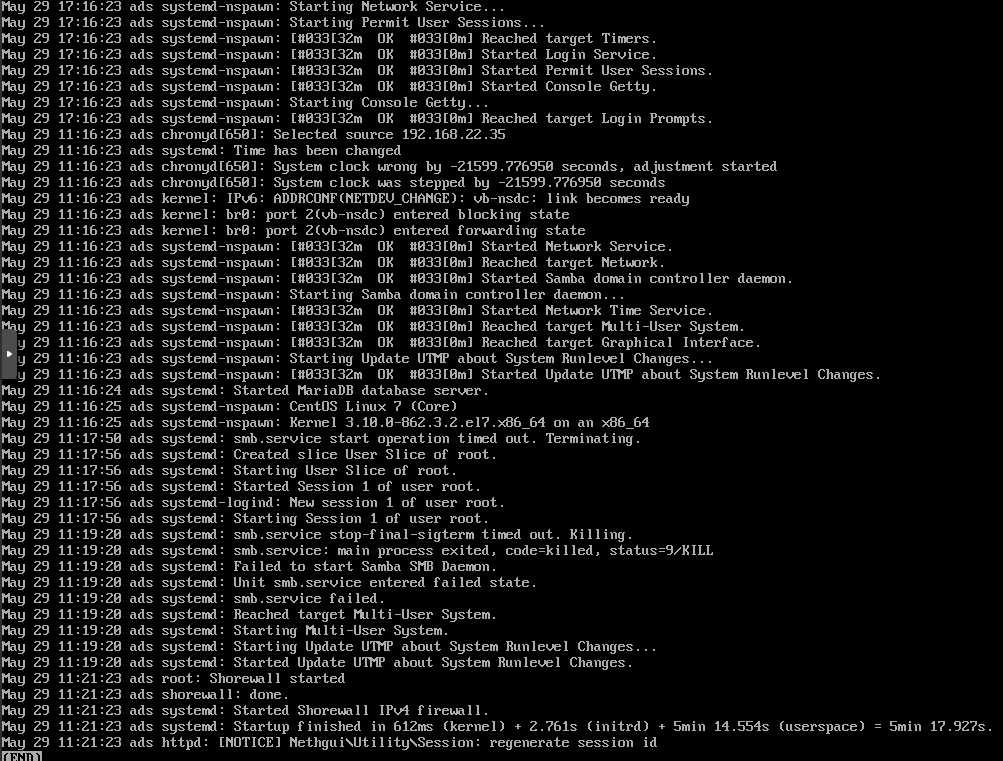
proxmox shows the VM running and the vm console shows this:
Looks like MariaDB refuses to going down nicely. And I see this kind of behavior since the upgrade.
It took almost 4 to 5 minutes to MariaDB to allow the server shutdown. (I can’t take the picture on time)
I don’t want to forceful reboot the proxmox server
I wonder if I restart proxmox without the VM shuting down correctly can be the cause of the dashboard failure.
The vm is down, restart proxmox
Proxmox is up
The VM is up
I can access the dashboard
The console shows:
After 4 minutes, the dashboard is unresponsive… I can’t access shared folders
I do a reboot from the VM’s console in proxmox, now I can access the dashboard:
Next try: *log off the dashboard, clean browser cache & cokies, then shutdown the vm, reboot proxmox ( are new steps) - but I don’t thing this issue is browser related, because I can’t access the shared folders from windows until I reboot the VM after the boot & failure.
I try another poweroff, and MariaDB still holds the shutdown process:
What can I do to fix this issue?
Thanks in advance.
3 days ago, I see this message: "disable the 2nd WAN"
So I remove the WAN interface (I don’t use right now); but the problem with MariaDB stop jobs prevails.
If I need to upload the logs (maria, messages); how can I do that?
I can, problem was that I didn’t understand that (oops! ); even with the help in Administration - Shutdown panel saying that:
Allows you to turn off or restart the server. It’s mandatory to shutdown the system before turning off the server. The execution of these functions takes a few minutes.
But I’m pretty sure that this is what sticks in my mind
WARNING! Clicking SHUTDOWN THE SYSTEM operation will start immediately.
Maybe to avoid this newbie mistake, the Administration - Shutdown panel needs a label saying this
The execution of these functions takes a few minutes.
Now I need to learn how to tell to proxmox to wait at least 5 minutes for the NS vm to shutdown.
@mrmarkuz; You believe that forcing the shutdown (NS/Proxmox) was the cause of the smb not starting correctly in my previous attempts?
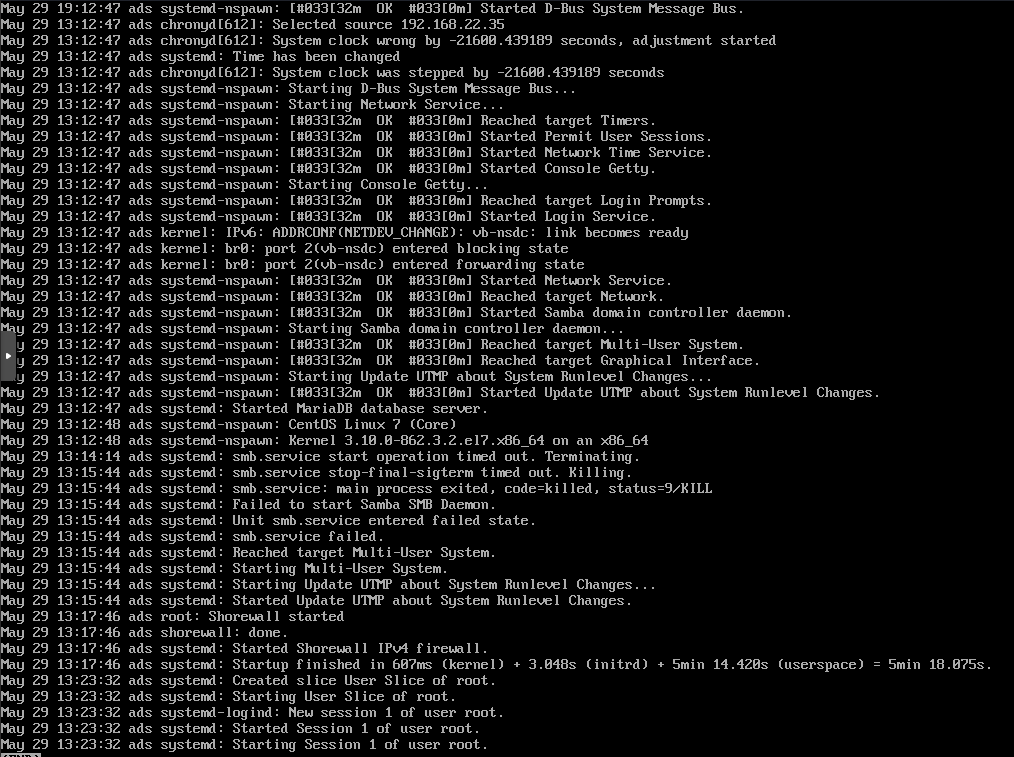
from messages:
May 29 11:17:56 ads systemd: Starting Session 1 of user root.
May 29 11:19:20 ads systemd: smb.service stop-final-sigterm timed out. Killing.
May 29 11:19:20 ads systemd: smb.service: main process exited, code=killed, status=9/KILL
May 29 11:19:20 ads systemd: Failed to start Samba SMB Daemon.
May 29 11:19:20 ads systemd: Unit smb.service entered failed state.
May 29 11:19:20 ads systemd: smb.service failed.
May 29 11:19:20 ads systemd: Reached target Multi-User System.
May 29 11:19:20 ads systemd: Starting Multi-User System.
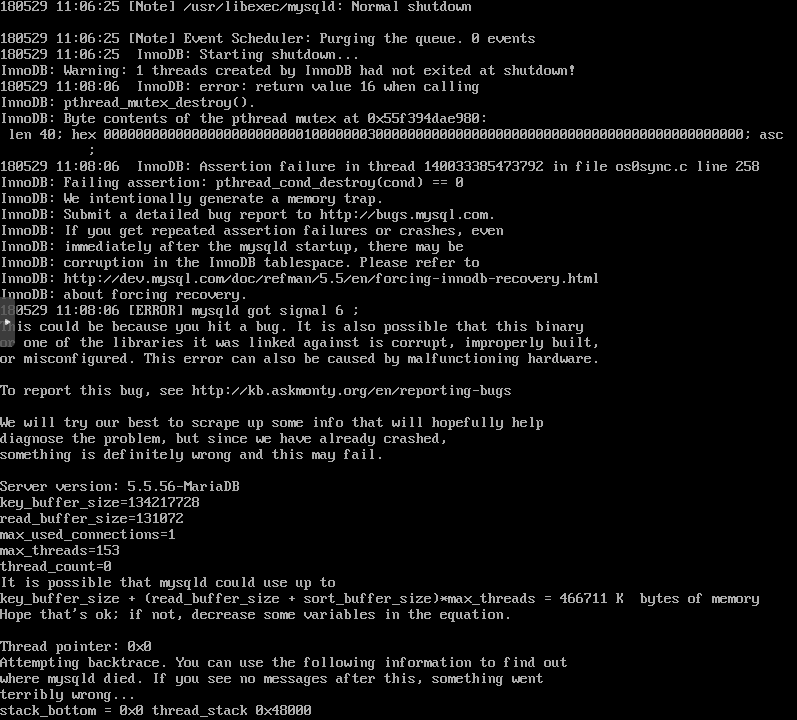
from mariadb.log
Version: '5.5.56-MariaDB' socket: '/var/lib/mysql/mysql.sock' port: 3306 MariaDB Server
180529 11:41:06 [Note] /usr/libexec/mysqld: Normal shutdown
180529 11:41:06 [Note] Event Scheduler: Purging the queue. 0 events
180529 11:41:06 InnoDB: Starting shutdown...
InnoDB: Warning: 1 threads created by InnoDB had not exited at shutdown!
180529 11:42:47 InnoDB: error: return value 16 when calling
InnoDB: pthread_mutex_destroy().
InnoDB: Byte contents of the pthread mutex at 0x558decdb2980:
len 40; hex 00000000000000000000000001000000030000000000000000000000000000000000000000000000; asc ;
180529 11:42:47 InnoDB: Assertion failure in thread 139679786755840 in file os0sync.c line 258
InnoDB: Failing assertion: pthread_cond_destroy(cond) == 0
InnoDB: We intentionally generate a memory trap.
InnoDB: Submit a detailed bug report to http://bugs.mysql.com.
InnoDB: If you get repeated assertion failures or crashes, even
InnoDB: immediately after the mysqld startup, there may be
InnoDB: corruption in the InnoDB tablespace. Please refer to
InnoDB: http://dev.mysql.com/doc/refman/5.5/en/forcing-innodb-recovery.html
InnoDB: about forcing recovery.
180529 11:42:47 [ERROR] mysqld got signal 6 ;
This could be because you hit a bug. It is also possible that this binary
or one of the libraries it was linked against is corrupt, improperly built,
or misconfigured. This error can also be caused by malfunctioning hardware.
To report this bug, see http://kb.askmonty.org/en/reporting-bugs
We will try our best to scrape up some info that will hopefully help
diagnose the problem, but since we have already crashed,
something is definitely wrong and this may fail.
Server version: 5.5.56-MariaDB
key_buffer_size=134217728
read_buffer_size=131072
max_used_connections=1
max_threads=153
thread_count=0
It is possible that mysqld could use up to
key_buffer_size + (read_buffer_size + sort_buffer_size)*max_threads = 466711 K bytes of memory
Hope that's ok; if not, decrease some variables in the equation.
Thread pointer: 0x0
Attempting backtrace. You can use the following information to find out
where mysqld died. If you see no messages after this, something went
terribly wrong...
stack_bottom = 0x0 thread_stack 0x48000
/usr/libexec/mysqld(my_print_stacktrace+0x3d)[0x558deb10e96d]
/usr/libexec/mysqld(handle_fatal_signal+0x515)[0x558dead24285]
/lib64/libpthread.so.0(+0xf6d0)[0x7f09c2dae6d0]
/lib64/libc.so.6(gsignal+0x37)[0x7f09c14d9277]
/lib64/libc.so.6(abort+0x148)[0x7f09c14da968]
/usr/libexec/mysqld(+0x2d764f)[0x558deab5964f]
/usr/libexec/mysqld(+0x728e45)[0x558deafaae45]
/usr/libexec/mysqld(+0x63eb1a)[0x558deaec0b1a]
/usr/libexec/mysqld(+0x5f4e75)[0x558deae76e75]
/usr/libexec/mysqld(_Z22ha_finalize_handlertonP13st_plugin_int+0x2c)[0x558dead2625c]
/usr/libexec/mysqld(+0x37d48f)[0x558deabff48f]
/usr/libexec/mysqld(+0x381ade)[0x558deac03ade]
/usr/libexec/mysqld(_Z15plugin_shutdownv+0x1cd)[0x558deac04bcd]
/usr/libexec/mysqld(+0x2ebb95)[0x558deab6db95]
/usr/libexec/mysqld(_Z10unireg_endv+0x2d)[0x558deab6f29d]
/usr/libexec/mysqld(+0x2ef95c)[0x558deab7195c]
/usr/libexec/mysqld(kill_server_thread+0xe)[0x558deab719ae]
/lib64/libpthread.so.0(+0x7e25)[0x7f09c2da6e25]
/lib64/libc.so.6(clone+0x6d)[0x7f09c15a1bad]
The manual page at http://dev.mysql.com/doc/mysql/en/crashing.html contains
information that should help you find out what is causing the crash.
180529 11:42:47 mysqld_safe Number of processes running now: 0
180529 11:42:47 mysqld_safe mysqld restarted
180529 11:42:47 [Note] /usr/libexec/mysqld (mysqld 5.5.56-MariaDB) starting as process 2104 ...
180529 11:42:47 InnoDB: The InnoDB memory heap is disabled
180529 11:42:47 InnoDB: Mutexes and rw_locks use GCC atomic builtins
180529 11:42:47 InnoDB: Compressed tables use zlib 1.2.7
180529 11:42:47 InnoDB: Using Linux native AIO
180529 11:42:47 InnoDB: Initializing buffer pool, size = 128.0M
180529 11:42:47 InnoDB: Completed initialization of buffer pool
180529 11:42:47 InnoDB: highest supported file format is Barracuda.
180529 11:42:47 InnoDB: Waiting for the background threads to start
180529 11:42:48 Percona XtraDB (http://www.percona.com) 5.5.52-MariaDB-38.3 started; log sequence number 1597991
180529 11:42:48 [Note] Plugin 'FEEDBACK' is disabled.
180529 11:42:48 [Note] Server socket created on IP: '0.0.0.0'.
180529 11:42:48 [Note] Event Scheduler: Loaded 0 events
180529 11:42:48 [Note] /usr/libexec/mysqld: ready for connections.
Version: '5.5.56-MariaDB' socket: '/var/lib/mysql/mysql.sock' port: 3306 MariaDB Server
180529 17:47:43 mysqld_safe Starting mysqld daemon with databases from /var/lib/mysq
I’m testing what I learn with all your help. And yes:
MariaDB takes 300 seconds for the system to stop.
Proxmox needs to know about this time to wait for the VM to shutdown.
In Proxmox, I need to edit the vm’s options, now Promox can:
wait 4 minutes to start the vm after a reboot.
wait 5 minutes and if the vm is down, so proxmox can reboot/shutdown
But the problem remains, after rebooting proxmox, the NS vm just don’t start correctly. I can’t access the dashboard, I can’t ssh from my own pc, but I can using a proxmox console, the messages log show this:
I don’t have another, but I can setup one:
nethserver? or anything like a windows or desktop Linux?
#1: The @GG_jr comments, make wonder about promox/NS issues when ballooning/RAM is used.
Next try will be: shutdown the vm + reboot proxmox; the vm with the 8GB (with ballooning disabled)
Result: After a restart of proxmox, all the services are up and working!
#2: Now I shut down all (Proxmox and vm) for a cold start.
Result: Success! Using this settings the NS vm starts fine:
I was thinking to re-test using ballooning and 8GB; but this definition is a good advice too:
Insanity: doing the same thing over and over again and expecting different results.