france
April 20, 2024, 7:43am
1
Hello everyone, I wanted to know if by restarting the system or shutting down, you can incur errors in the file system. I am writing this because there is no correct system closure procedure like ns7. or am I wrong?
mrmarkuz
April 20, 2024, 8:53am
2
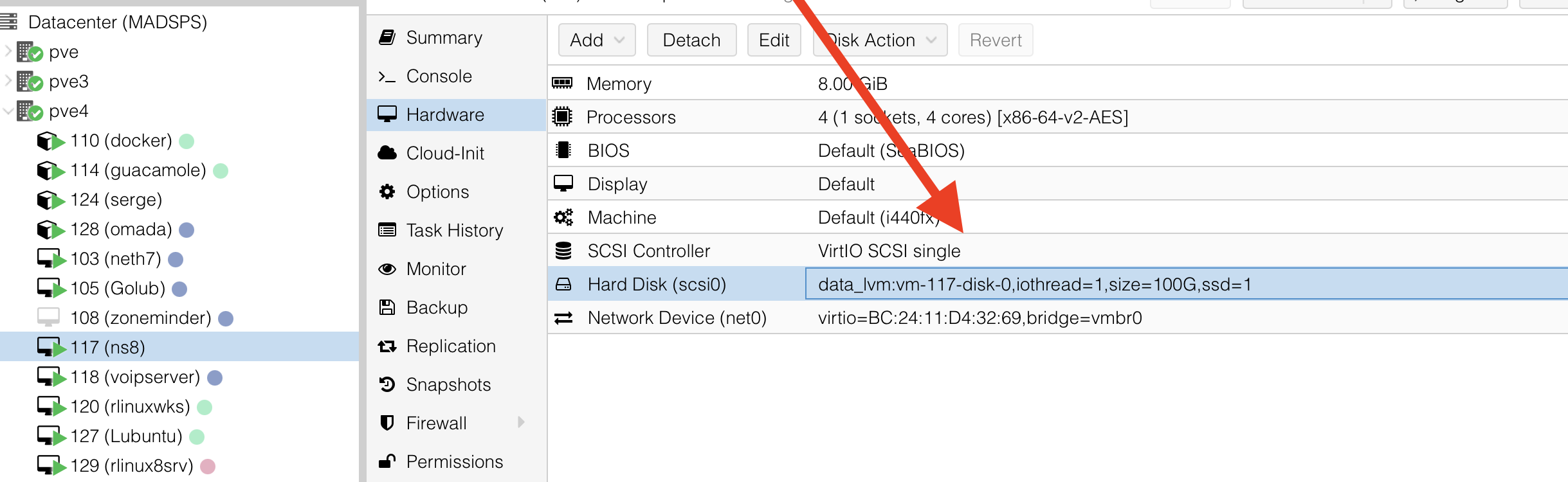
I’m going to reproduce your setup this weekend to test Rocky on Proxmox using a qcow disk on a xigmanas NFS.
NS8 uses the system shutdown procedure of the distro (as NS7 did) so I don’t think that’s the issue.
Maybe you can find a solution in this thread:
opened 02:02PM - 21 Nov 19 UTC
closed 01:22PM - 22 Nov 19 UTC
kind/bug
locked - please file new issue/PR
/kind bug
**Description**
podman push fails with
* "error unmounting /va… r/lib/containers/storage/overlay/5b8acfe925e03f8a94a5e5350a5fd82312a2874a2031cc14f963b857096009c1/merged: invalid argument"
* ...
* Error: Error copying image to the remote destination: Error reading blob sha256:49f80dff343c4e335edd514183872788671fe3d00492380c190a09c9c1b46c72: error creating overlay mount to /var/lib/containers/storage/overlay/3ab8392de799e2ac9cb455baf11b7f2d0f32d63b54dee5e725eca0136cef299b/merged: device or resource busy
**Describe the results you received:**
```
+ sudo podman push quay.io/fedora-dotnet/dotnet:3.1
Getting image source signatures
Copying blob sha256:d5c4792b7b09ad540a878569fc25faf9f43b19b8b2935f6cee4a3aba4ec76fc6
time="2019-11-20T19:06:23Z" level=error msg="error unmounting /var/lib/containers/storage/overlay/cb321239cf202dadb69564ceafe82a9813a2dad3cc5fbc1b78dd1a255e8718bb/merged: invalid argument"
Copying blob sha256:cf768f432945daf5207b1c42964875efc7350cad6bc67180128cc9cc80ed6948
Copying blob sha256:2ae3cee18c8ef9e0d448649747dab81c4f1ca2714a8c4550eff49574cab262c9
time="2019-11-20T19:06:23Z" level=error msg="error unmounting /var/lib/containers/storage/overlay/3ab8392de799e2ac9cb455baf11b7f2d0f32d63b54dee5e725eca0136cef299b/merged: invalid argument"
time="2019-11-20T19:06:23Z" level=error msg="error unmounting /var/lib/containers/storage/overlay/0c2b7a8835318870d74c0d0de3223112c256dc9dbfe4df8f5a7731f6fff0a103/merged: invalid argument"
time="2019-11-20T19:06:23Z" level=error msg="error unmounting /var/lib/containers/storage/overlay/5b8acfe925e03f8a94a5e5350a5fd82312a2874a2031cc14f963b857096009c1/merged: invalid argument"
time="2019-11-20T19:06:23Z" level=error msg="error unmounting /var/lib/containers/storage/overlay/c44255f3bf3ab0967b184c9d8808c5e4b4f020ebfd83ed1519e09f05a1393865/merged: invalid argument"
time="2019-11-20T19:06:23Z" level=error msg="error unmounting /var/lib/containers/storage/overlay/12bcba531f544a013fbf17c9aaa7b69fd284020a7ea2dabcde2a1cdbb876ea58/merged: invalid argument"
time="2019-11-20T19:06:23Z" level=error msg="error unmounting /var/lib/containers/storage/overlay/cdedbabb2fc4f8d0cad5bff0c1fe993ac699845c81df2176e333ed716f967ac5/merged: invalid argument"
time="2019-11-20T19:06:23Z" level=error msg="error unmounting /var/lib/containers/storage/overlay/97e1ac207e49e809759bb28c19d7dd709b6fd2f54b82df65d9e5cc2aa9fb4f8c/merged: invalid argument"
time="2019-11-20T19:06:23Z" level=error msg="error unmounting /var/lib/containers/storage/overlay/51d41a6437db18db1fc2fec7b0225c3a44a9e2afdc7fda4cf659c796efc736a0/merged: invalid argument"
time="2019-11-20T19:06:23Z" level=error msg="error unmounting /var/lib/containers/storage/overlay/e1d0f2e91c4cdf590a1041b83fe20a5e48aeaea76e7910fe08198064bdbbe917/merged: invalid argument"
Error: Error copying image to the remote destination: Error reading blob sha256:49f80dff343c4e335edd514183872788671fe3d00492380c190a09c9c1b46c72: error creating overlay mount to /var/lib/containers/storage/overlay/3ab8392de799e2ac9cb455baf11b7f2d0f32d63b54dee5e725eca0136cef299b/merged: device or resource busy
```
**Describe the results you expected:**
**Environment**:
Fedora 30 in VM.
`Linux localhost.localdomain 5.2.9-200.fc30.x86_64 #1 SMP Fri Aug 16 21:37:45 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux`
`podman 2:1.6.2-2.fc30`
france
April 20, 2024, 9:21am
3
Ok , but rocky with the installation of Ns8 of course . As written I have 2 rocky linux, moreover credited on ns7 and I launched snaps … never had a problem. Instead I believe it is the reboot or shutdown procedure that causes this. No one at the moment answered me when you restart or turn off rocky, ns8 closes all disk writes or anything … If this is not the case, it is equivalent to brutally turning off the server.
france
April 20, 2024, 9:24am
4
In addition, at the moment I managed to make the apps I had on ns7 work, so the migration from ns7 to ns8 in my personal point of view applies only to domain users and then transfer the entire ns7 domain to 8, the rest has to be arranged. But considering the structure of ns8 it cannot be claimed otherwise they are two different products for different uses.
mrmarkuz
April 21, 2024, 9:48pm
5
I heavily tested, did a snapshot, did a backup to PBS, stopped the machine while restarting a service but I couldn’t reproduce the error yet.
In my test environment I just use a GB LAN connection to the xigmanas which slows down a lot and could trigger issues.
Did you already try to setup a fresh NS8 on a local Proxmox node instead of the NAS? Just to see if the issue is coming back…
france
April 22, 2024, 5:45am
6
mrmarkuz:
I heavily tested, did a snapshot, did a backup to PBS, stopped the machine while restarting a service but I couldn’t reproduce the error yet.
In my test environment I just use a GB LAN connection to the xigmanas which slows down a lot and could trigger issues.
Did you already try to setup a fresh NS8 on a local Proxmox node instead of the NAS? Just to see if the issue is coming back…
Hi Mark, thank you for trying to do some tests. No, I haven’t tried yet. My ns8 at the moment works without problem , but without having launched anything or restarted the server . The virtual disk is of type qcow2 on nfs ( zfs on hpnas ) . I could in the day try to restart the base system ( rocky 9 ) and see after the reboot what happens . I’ll let you know later. Thank you for the time you’ve dedicated.
1 Like
france
April 22, 2024, 6:01am
7
Anyway Mark, I haven’t restarted or snap in three days. If there was actually a problem managing the server in nfs on nas , in these 3 days I should have had errors again . I’m trying nextcloud roundcube glpi wordpress and I’m using them as if they were in production, they work without problems including piwigo for photos. I’m sure if I had to restart , so from rocky linux “reboot” , when I restart I might have surprises . However, as written before after I try again. But do you think if rocky restarts, is the ns8 server shut down in a brutal way or is a correct system shutdown?
mrmarkuz
April 22, 2024, 6:45am
8
It’s a correct shutdown. You can watch in Proxmox console.
Even just stopping the VM (without shutdown) wasn’t an issue.
davidep
April 22, 2024, 7:37am
9
Ciao Francesco,
1 Like
mrmarkuz
April 22, 2024, 8:18am
10
I got the “invalid argument” error again on my NS8 Rocky dev test machine…
Here are the logs:
gistfile1.txt
2024-04-22T09:58:27+02:00 [1:zammad3:systemd] Started libcrun container.
2024-04-22T09:58:27+02:00 [1:zammad3:zammad3] 5e16ca948c21561d59e210f84ae8a358c70e33f6c2a90f33ca589dc09305cf1b
2024-04-22T09:58:27+02:00 [1:zammad3:systemd] Started Podman zammad-redis.service.
2024-04-22T09:58:27+02:00 [1:zammad3:systemd] Starting Podman zammad-init.service...
2024-04-22T09:58:28+02:00 [1:zammad3:systemd] Starting Podman zammad-railsserver.service...
2024-04-22T09:58:28+02:00 [1:zammad3:systemd] Starting Podman zammad-scheduler.service...
2024-04-22T09:58:28+02:00 [1:zammad3:systemd] Starting Podman zammad-websocket.service...
2024-04-22T09:58:28+02:00 [1:zammad3:zammad-redis] 1:C 22 Apr 2024 07:58:28.036 # WARNING Memory overcommit must be enabled! Without it, a background save or replication may fail under low memory condition. Being disabled, it can also cause failures without low memory condition, see https://github.com/jemalloc/jemalloc/issues/1328. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
2024-04-22T09:58:28+02:00 [1:zammad3:zammad-redis] 1:C 22 Apr 2024 07:58:28.037 * oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
2024-04-22T09:58:28+02:00 [1:zammad3:zammad-redis] 1:C 22 Apr 2024 07:58:28.037 * Redis version=7.2.4, bits=64, commit=00000000, modified=0, pid=1, just startedshow original
Solvable by removing the merged dirs and restarting the services:
rmdir /home/zammad3/.local/share/containers/storage/overlay/*/merged
2 Likes
france
April 22, 2024, 8:51am
11
Finally ! So mark is there a underlying problem that has nothing to do with snap reboot or something?
france
April 22, 2024, 9:03am
12
Hi Davide, Mark has already done it.
davidep
April 22, 2024, 9:04am
13
Yes it is a Podman bug. Ensure you have the latest updates. Hopefully in RL 9.4 Podman 4.9 will receive more fixes than the 4.6.1 branch.
committed 06:26AM - 06 Oct 23 UTC
1 Like
france
April 22, 2024, 9:13am
14
I frequently perform updates, but I think this is a really important bug as in every restart or other situation the server is unusable unless you proceed with the deletion of the merged . Now I am more serene as the doubt of nfs, snapshots and more has been excluded. Thank you .
france
April 22, 2024, 12:15pm
16
So much the better! Visot that I assume that a cluster is in a SAN , at least in the middle of the world. Anyway, thank you for your intervention that has satiated all my doubts and not just mine.
france
April 23, 2024, 2:27pm
17
I tried to move the qcow2 disk from nfs to local storage .
# rmdir /home/traefik1/.local/share/containers/storage/overlay/*/merged
runagent -m traefik1 systemctl --user restart traefik
After is ok .
1 Like
davidep
May 2, 2024, 1:58pm
18
For the bug fix, a boot script can apply the workaround automatically, until we receive the upstream patched releases in Rocky Linux 9.4 and Debian 13 (Trixie).
opened 09:28AM - 02 May 24 UTC
bug
**Steps to reproduce**
on rocky linux, not always reproducible
- Install a m… ail server with ldap, samba-ad, mail, some rootless module and configure them
- let the server runs during few days
- reboot the server
**Expected behavior**
I expect that the reboot starts all modules without issue
**Actual behavior**
It seems that when we start the server, before to start any user service we try to unmount a merged volume. It seems it is a random side effect, some user systemd service fails to unmount it, others succeed
I have seen this failure for openldap, sambaAD, clamav but I others experimented it for rspamd and postfix, all occurred after the reboot
we could found this for instance in my case
```
May 02 09:51:29 R1-pve.rocky9-pve.org systemd[2040]: Starting Samba AD Domain Controller...
May 02 09:51:29 R1-pve.rocky9-pve.org podman[6068]: time="2024-05-02T09:51:29+02:00" level=warning msg="Unmounting container \"samba-dc\" while attempting to delete storage: unmounting \"/home/samba1/.local/share/containers/storage/overlay/c07c970255101ffff8fb38162c32beb7ef7884f8d>
May 02 09:51:29 R1-pve.rocky9-pve.org podman[6068]: Error: removing storage for container "samba-dc": unmounting "/home/samba1/.local/share/containers/storage/overlay/c07c970255101ffff8fb38162c32beb7ef7884f8d1a12f4cdd0da18adc1c4873/merged": invalid argument
May 02 09:51:29 R1-pve.rocky9-pve.org systemd[2040]: samba-dc.service: Control process exited, code=exited, status=125/n/a
May 02 09:51:29 R1-pve.rocky9-pve.org systemd[2040]: samba-dc.service: Failed with result 'exit-code'.
May 02 09:51:29 R1-pve.rocky9-pve.org systemd[2040]: Failed to start Samba AD Domain Controller.
```
and
```
May 02 09:51:27 R1-pve.rocky9-pve.org systemd[2039]: Starting OpenLDAP directory server...
May 02 09:51:27 R1-pve.rocky9-pve.org podman[4026]: time="2024-05-02T09:51:27+02:00" level=warning msg="Unmounting container \"openldap\" while attempting to delete storage: unmounting \"/home/openldap1/.local/share/containers/storage/overlay/401b7a7b2369e7283b6ee84ceeb976bef569d7>
May 02 09:51:27 R1-pve.rocky9-pve.org podman[4026]: Error: removing storage for container "openldap": unmounting "/home/openldap1/.local/share/containers/storage/overlay/401b7a7b2369e7283b6ee84ceeb976bef569d7d221a3b57207ce9d063acc75a7/merged": invalid argument
May 02 09:51:27 R1-pve.rocky9-pve.org systemd[2039]: openldap.service: Control process exited, code=exited, status=125/n/a
May 02 09:51:27 R1-pve.rocky9-pve.org systemd[2039]: openldap.service: Failed with result 'exit-code'.
May 02 09:51:27 R1-pve.rocky9-pve.org systemd[2039]: Failed to start OpenLDAP directory server.
```
reboot of the server at 09:48:14
https://gist.github.com/stephdl/697992bd89198a8bf8673593e0717582
The immediate fix is to rm the merged volumes
`runagent -m openldap1 rm -rf ../../.local/share/containers/storage/overlay/*/merged/`
however if you try to reboot, the issue is not reproducible as is, it might occur again, or it might occur to another module
```
[root@R1-pve ~]# podman info
host:
arch: amd64
buildahVersion: 1.31.3
cgroupControllers:
- cpuset
- cpu
- io
- memory
- hugetlb
- pids
- rdma
- misc
cgroupManager: systemd
cgroupVersion: v2
conmon:
package: conmon-2.1.8-1.el9.x86_64
path: /usr/bin/conmon
version: 'conmon version 2.1.8, commit: cebaba63f66de0e92cdc7e2a59f39c9208281158'
cpuUtilization:
idlePercent: 99.75
systemPercent: 0.07
userPercent: 0.18
cpus: 8
databaseBackend: boltdb
distribution:
distribution: '"rocky"'
version: "9.3"
eventLogger: journald
freeLocks: 2042
hostname: R1-pve.rocky9-pve.org
idMappings:
gidmap: null
uidmap: null
kernel: 5.14.0-362.24.1.el9_3.0.1.x86_64
linkmode: dynamic
logDriver: journald
memFree: 4394389504
memTotal: 8057622528
networkBackend: netavark
networkBackendInfo:
backend: netavark
dns:
package: aardvark-dns-1.7.0-1.el9.x86_64
path: /usr/libexec/podman/aardvark-dns
version: aardvark-dns 1.7.0
package: netavark-1.7.0-2.el9_3.x86_64
path: /usr/libexec/podman/netavark
version: netavark 1.7.0
ociRuntime:
name: crun
package: crun-1.8.7-1.el9.x86_64
path: /usr/bin/crun
version: |-
crun version 1.8.7
commit: 53a9996ce82d1ee818349bdcc64797a1fa0433c4
rundir: /run/user/0/crun
spec: 1.0.0
+SYSTEMD +SELINUX +APPARMOR +CAP +SECCOMP +EBPF +CRIU +YAJL
os: linux
pasta:
executable: ""
package: ""
version: ""
remoteSocket:
path: /run/podman/podman.sock
security:
apparmorEnabled: false
capabilities: CAP_CHOWN,CAP_DAC_OVERRIDE,CAP_FOWNER,CAP_FSETID,CAP_KILL,CAP_NET_BIND_SERVICE,CAP_SETFCAP,CAP_SETGID,CAP_SETPCAP,CAP_SETUID,CAP_SYS_CHROOT
rootless: false
seccompEnabled: true
seccompProfilePath: /usr/share/containers/seccomp.json
selinuxEnabled: true
serviceIsRemote: false
slirp4netns:
executable: /usr/bin/slirp4netns
package: slirp4netns-1.2.1-1.el9.x86_64
version: |-
slirp4netns version 1.2.1
commit: 09e31e92fa3d2a1d3ca261adaeb012c8d75a8194
libslirp: 4.4.0
SLIRP_CONFIG_VERSION_MAX: 3
libseccomp: 2.5.2
swapFree: 6874460160
swapTotal: 6874460160
uptime: 1h 33m 22.00s (Approximately 0.04 days)
plugins:
authorization: null
log:
- k8s-file
- none
- passthrough
- journald
network:
- bridge
- macvlan
- ipvlan
volume:
- local
registries:
search:
- registry.access.redhat.com
- registry.redhat.io
- docker.io
store:
configFile: /etc/containers/storage.conf
containerStore:
number: 3
paused: 0
running: 3
stopped: 0
graphDriverName: overlay
graphOptions:
overlay.mountopt: nodev,metacopy=on
graphRoot: /var/lib/containers/storage
graphRootAllocated: 40811614208
graphRootUsed: 2911166464
graphStatus:
Backing Filesystem: xfs
Native Overlay Diff: "false"
Supports d_type: "true"
Using metacopy: "true"
imageCopyTmpDir: /var/tmp
imageStore:
number: 13
runRoot: /run/containers/storage
transientStore: false
volumePath: /var/lib/containers/storage/volumes
version:
APIVersion: 4.6.1
Built: 1709719721
BuiltTime: Wed Mar 6 11:08:41 2024
GitCommit: ""
GoVersion: go1.20.12
Os: linux
OsArch: linux/amd64
Version: 4.6.1
```
and for the user openldap1
```
[root@R1-pve ~]# runagent -m samba1
runagent: [INFO] starting bash -l
runagent: [INFO] working directory: /home/samba1/.config/state
[samba1@R1-pve state]$ podman ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[samba1@R1-pve state]$ podman info
host:
arch: amd64
buildahVersion: 1.31.3
cgroupControllers:
- memory
- pids
cgroupManager: systemd
cgroupVersion: v2
conmon:
package: conmon-2.1.8-1.el9.x86_64
path: /usr/bin/conmon
version: 'conmon version 2.1.8, commit: cebaba63f66de0e92cdc7e2a59f39c9208281158'
cpuUtilization:
idlePercent: 94.48
systemPercent: 1.59
userPercent: 3.93
cpus: 8
databaseBackend: boltdb
distribution:
distribution: '"rocky"'
version: "9.3"
eventLogger: file
freeLocks: 2044
hostname: R1-pve.rocky9-pve.org
idMappings:
gidmap:
- container_id: 0
host_id: 1004
size: 1
- container_id: 1
host_id: 362144
size: 65536
uidmap:
- container_id: 0
host_id: 1004
size: 1
- container_id: 1
host_id: 362144
size: 65536
kernel: 5.14.0-362.24.1.el9_3.0.1.x86_64
linkmode: dynamic
logDriver: journald
memFree: 6383128576
memTotal: 8057618432
networkBackend: netavark
networkBackendInfo:
backend: netavark
dns:
package: aardvark-dns-1.7.0-1.el9.x86_64
path: /usr/libexec/podman/aardvark-dns
version: aardvark-dns 1.7.0
package: netavark-1.7.0-2.el9_3.x86_64
path: /usr/libexec/podman/netavark
version: netavark 1.7.0
ociRuntime:
name: crun
package: crun-1.8.7-1.el9.x86_64
path: /usr/bin/crun
version: |-
crun version 1.8.7
commit: 53a9996ce82d1ee818349bdcc64797a1fa0433c4
rundir: /run/user/1004/crun
spec: 1.0.0
+SYSTEMD +SELINUX +APPARMOR +CAP +SECCOMP +EBPF +CRIU +YAJL
os: linux
pasta:
executable: ""
package: ""
version: ""
remoteSocket:
path: /run/user/1004/podman/podman.sock
security:
apparmorEnabled: false
capabilities: CAP_CHOWN,CAP_DAC_OVERRIDE,CAP_FOWNER,CAP_FSETID,CAP_KILL,CAP_NET_BIND_SERVICE,CAP_SETFCAP,CAP_SETGID,CAP_SETPCAP,CAP_SETUID,CAP_SYS_CHROOT
rootless: true
seccompEnabled: true
seccompProfilePath: /usr/share/containers/seccomp.json
selinuxEnabled: true
serviceIsRemote: false
slirp4netns:
executable: /usr/bin/slirp4netns
package: slirp4netns-1.2.1-1.el9.x86_64
version: |-
slirp4netns version 1.2.1
commit: 09e31e92fa3d2a1d3ca261adaeb012c8d75a8194
libslirp: 4.4.0
SLIRP_CONFIG_VERSION_MAX: 3
libseccomp: 2.5.2
swapFree: 6874460160
swapTotal: 6874460160
uptime: 0h 2m 48.00s
plugins:
authorization: null
log:
- k8s-file
- none
- passthrough
- journald
network:
- bridge
- macvlan
- ipvlan
volume:
- local
registries:
search:
- registry.access.redhat.com
- registry.redhat.io
- docker.io
store:
configFile: /home/samba1/.config/containers/storage.conf
containerStore:
number: 0
paused: 0
running: 0
stopped: 0
graphDriverName: overlay
graphOptions: {}
graphRoot: /home/samba1/.local/share/containers/storage
graphRootAllocated: 19925041152
graphRootUsed: 9575915520
graphStatus:
Backing Filesystem: xfs
Native Overlay Diff: "true"
Supports d_type: "true"
Using metacopy: "false"
imageCopyTmpDir: /var/tmp
imageStore:
number: 1
runRoot: /run/user/1004/containers
transientStore: false
volumePath: /home/samba1/.local/share/containers/storage/volumes
version:
APIVersion: 4.6.1
Built: 1709719721
BuiltTime: Wed Mar 6 11:08:41 2024
GitCommit: ""
GoVersion: go1.20.12
Os: linux
OsArch: linux/amd64
Version: 4.6.1
```
**Components**
podman 4.6.1
**See also**
https://community.nethserver.org/t/mail-cannot-retrieve-filter-configuration/23484
https://community.nethserver.org/t/ns8-merged-error/23386
3 Likes
davidep
May 2, 2024, 2:06pm
19
It would be important to know if sombody hit the same bug on Debian 12!
Debian users, please share your experience.
No more problems on Rocky 9.3 after two reboots.
Thank you