How many ressources do you allocate to your vm(core,ram)
I think I could reproduce the error.
I used this rocky vmdk image in an ESXi VM in VMWare Workstation with 2 CPUs and 4GB RAM, it was converted from the original qcow2 image.
I didn’t update the system and in Rocky 9.1 everything worked. I configured the webserver and could reach a virtual host web page without issues.
Then I updated to Rocky 9.2, rebooted and wasn’t able to configure the webserver this time. The web page is still reachable.
Error output from web UI:
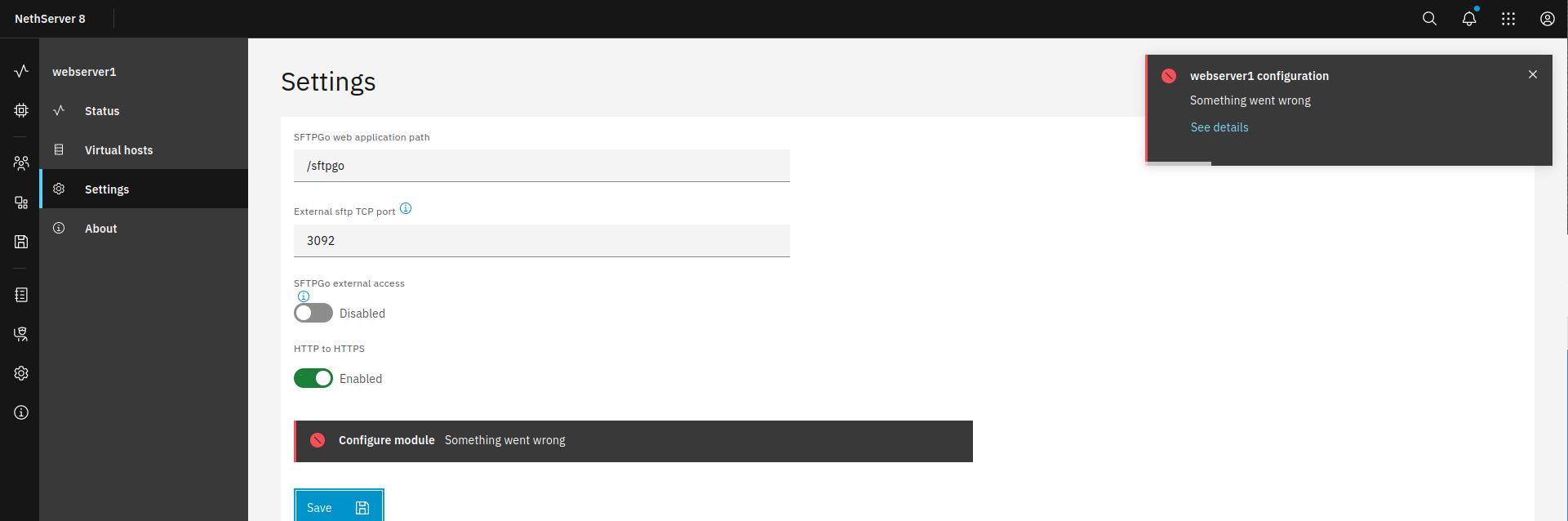
Details:
{
"context": {
"action": "configure-module",
"data": {
"http2https": true,
"path": "/sftpgo",
"sftp_tcp_port": 3092,
"sftpgo_service": false
},
"extra": {
"description": "Configuring...",
"title": "webserver1 configuration"
},
"id": "6f98c65b-a07e-43e6-b933-2dab52ead583",
"parent": "",
"queue": "module/webserver1/tasks",
"timestamp": "2023-06-07T07:44:40.26480503Z",
"user": "admin"
},
"status": "aborted",
"progress": 40,
"subTasks": [],
"validated": true,
"result": {
"error": "<7>dump_env() is deprecated and implemented as a no-op\nTraceback (most recent call last):\n File \"/home/webserver1/.config/actions/configure-module/20traefik\", line 54, in <module>\n response = agent.tasks.run(\n File \"/usr/local/agent/pypkg/agent/tasks/run.py\", line 39, in run\n results = runp([taskrq], **kwargs)\n File \"/usr/local/agent/pypkg/agent/tasks/run.py\", line 50, in runp\n return asyncio.run(_runp(tasks, **kwargs))\n File \"/usr/lib64/python3.9/asyncio/runners.py\", line 44, in run\n return loop.run_until_complete(main)\n File \"/usr/lib64/python3.9/asyncio/base_events.py\", line 647, in run_until_complete\n return future.result()\n File \"/usr/local/agent/pypkg/agent/tasks/run.py\", line 120, in _runp\n return await asyncio.gather(*runners, return_exceptions=(len(tasks) > 1))\n File \"/usr/local/agent/pypkg/agent/tasks/run.py\", line 129, in _run_with_protocol\n return await run_apiclient(taskrq, **pconn)\n File \"/usr/local/agent/pypkg/agent/tasks/apiclient.py\", line 47, in run_apiclient\n taskctx['status_path'] = await _retry_request(_apost_task, taskrq, client=client, theaders=theaders, **kwargs)\n File \"/usr/local/agent/pypkg/agent/tasks/apiclient.py\", line 191, in _retry_request\n raise exhttp\n File \"/usr/local/agent/pypkg/agent/tasks/apiclient.py\", line 166, in _retry_request\n retval = await request_procedure(*args, **kwargs)\n File \"/usr/local/agent/pypkg/agent/tasks/apiclient.py\", line 246, in _apost_task\n async with client.post(\n File \"/usr/local/agent/pyenv/lib64/python3.9/site-packages/aiohttp/client.py\", line 1117, in __aenter__\n self._resp = await self._coro\n File \"/usr/local/agent/pyenv/lib64/python3.9/site-packages/aiohttp/client.py\", line 625, in _request\n resp.raise_for_status()\n File \"/usr/local/agent/pyenv/lib64/python3.9/site-packages/aiohttp/client_reqrep.py\", line 1000, in raise_for_status\n raise ClientResponseError(\naiohttp.client_exceptions.ClientResponseError: 403, message='Forbidden', url=URL('http://cluster-leader:9311/api/module/traefik1/tasks')\n",
"exit_code": 1,
"file": "task/module/webserver1/6f98c65b-a07e-43e6-b933-2dab52ead583",
"output": ""
}
}
Your error is differerent traefik is unresponsive
1 Like
I guess the prebuilt images got issues
1 Like
Or redis
Check wich container is down
Redis is run by root traefik by the user traefik1
Redis (container) seems running:
[root@rocky1 ~]# systemctl status redis
● redis.service - Core Redis DB
Loaded: loaded (/etc/systemd/system/redis.service; enabled; preset: disabled)
Active: active (running) since Wed 2023-06-07 07:40:23 UTC; 1h 2min ago
Docs: https://github.com/NethServer/ns8-core
Process: 1284 ExecStartPre=/bin/rm -f /run/redis.pid /run/redis.cid (code=exited, status=0/SUCCESS)
Process: 1291 ExecStart=/usr/bin/podman run --conmon-pidfile=/run/redis.pid --cidfile=/run/redis.cid --cgroups=no-conmon --detach --log-opt=tag=redis --replace --name=redis --network=host --volume=redis-data:/data ${REDIS_IMAGE} (cod>
Process: 1410 ExecStartPost=/usr/bin/bash -c while ! exec 3<>/dev/tcp/127.0.0.1/6379; do sleep 1 ; done (code=exited, status=0/SUCCESS)
Process: 1640 ExecStartPost=/usr/local/bin/acl-load (code=exited, status=0/SUCCESS)
Process: 1802 ExecStartPost=/usr/local/sbin/apply-vpn-routes (code=exited, status=0/SUCCESS)
Main PID: 1365 (conmon)
Tasks: 1 (limit: 22978)
Memory: 1.2M
CPU: 1.193s
CGroup: /system.slice/redis.service
└─1365 /usr/bin/conmon --api-version 1 -c 4c49723116694813d5ac19bb2f8c82ac5bcaea74c3957b200bfa8d6e4f29058f -u 4c49723116694813d5ac19bb2f8c82ac5bcaea74c3957b200bfa8d6e4f29058f -r /usr/bin/crun -b /var/lib/containers/storage/o>
Jun 07 08:34:30 rocky1.mrmarkuz.ddnss.eu redis[1365]: 1:M 07 Jun 2023 08:34:30.847 * 1 changes in 5 seconds. Saving...
Jun 07 08:34:30 rocky1.mrmarkuz.ddnss.eu redis[1365]: 1:M 07 Jun 2023 08:34:30.853 * Background saving started by pid 36
Jun 07 08:34:30 rocky1.mrmarkuz.ddnss.eu redis[1365]: 36:C 07 Jun 2023 08:34:30.896 * DB saved on disk
Jun 07 08:34:30 rocky1.mrmarkuz.ddnss.eu redis[1365]: 36:C 07 Jun 2023 08:34:30.897 * Fork CoW for RDB: current 0 MB, peak 0 MB, average 0 MB
Jun 07 08:34:30 rocky1.mrmarkuz.ddnss.eu redis[1365]: 1:M 07 Jun 2023 08:34:30.954 * Background saving terminated with success
Jun 07 08:34:36 rocky1.mrmarkuz.ddnss.eu redis[1365]: 1:M 07 Jun 2023 08:34:36.092 * 1 changes in 5 seconds. Saving...
Jun 07 08:34:36 rocky1.mrmarkuz.ddnss.eu redis[1365]: 1:M 07 Jun 2023 08:34:36.098 * Background saving started by pid 37
Jun 07 08:34:36 rocky1.mrmarkuz.ddnss.eu redis[1365]: 37:C 07 Jun 2023 08:34:36.128 * DB saved on disk
Jun 07 08:34:36 rocky1.mrmarkuz.ddnss.eu redis[1365]: 37:C 07 Jun 2023 08:34:36.129 * Fork CoW for RDB: current 0 MB, peak 0 MB, average 0 MB
Jun 07 08:34:36 rocky1.mrmarkuz.ddnss.eu redis[1365]: 1:M 07 Jun 2023 08:34:36.200 * Background saving terminated with success
[root@rocky1 ~]# podman ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d4be049d94e1 docker.io/grafana/promtail:2.7.3 -config.file=/etc... About an hour ago Up About an hour promtail1
4c4972311669 ghcr.io/nethserver/redis:1.0.1 redis-server /dat... About an hour ago Up About an hour redis
Traefik container is running:
[root@rocky1 ~]# ssh traefik1@localhost
Last login: Wed Jun 7 08:42:18 2023 from ::1
[traefik1@rocky1 ~]$ podman ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
25d47586c536 docker.io/library/traefik:v2.9 traefik About an hour ago Up About an hour traefik
The error is still reproducible ?
Yes, it is.
EDIT:
The error also occurs when using Rocky 9.1 without upgrading to 9.2.
After installing the webserver, configuration works but after reboot it doesn’t work anymore.
1 Like
could you try with a minimal installation iso of rocky linux then initiate the cluster ?
web server 1.0.3 install log on VM 4 cores and 8GB RAM rocky-linux minimal install
configure webserver
I cannot reproduce your issue
Question ![]()
why do you have made your prebuilt image why do you not use the official prebuilt image ?
I just converted the official qcow2 image to vmdk to be able to use it with vmware, see NS8: All VMWare images unusable - #10 by mrmarkuz
I didn’t build an image.
I’m going to test Rocky from ISO later today…
2 Likes
the boot stucks on probing EDD(edd=off to disable)
If you’re using ESXi/Workstation you need to set the hard disk on an IDE controller,
EDIT:
Related issue:
What exactly did you try?
2 Likes
yes I set SATA on proxmox, also I changed the cpu default type KVM64, for now I test the qcow
If using RHEL distro like Rocky on Proxmox you need to change CPU to something else, see Installation — NS8 documentation
When using RHEL-based images on Proxmox, change the default CPU model to anything other than
kvm64
I use SandyBridge or G5_Opteron, depending on CPU. Host should work too.
1 Like
honestly I am not a big fan of prebuilt image ![]()
what is the default partition size ?
1 Like
The default size is 10GB. I kept it even if 20GB is the minimum requirement.
After resizing the disk you need to start the VM twice, the first time it doesn’t boot.
2 Likes
well still not fan of it ![]()
However with the qcow image web server is up and configured smoothly
1 Like
4 core and 8 GB of ram, however few used ![]() 1.2G
1.2G
1 Like