I clicked to apply the latest core update, which appeared to stall at 16%. After some time, when this appear to be not moving along I went to the Logs page and started poking around to see if anything seemed out of place. In the logs I saw a large number of “permission denied” errors. After clicking around the menus a little more, the whole admin interface locked up and wouldn’t respond to anything.
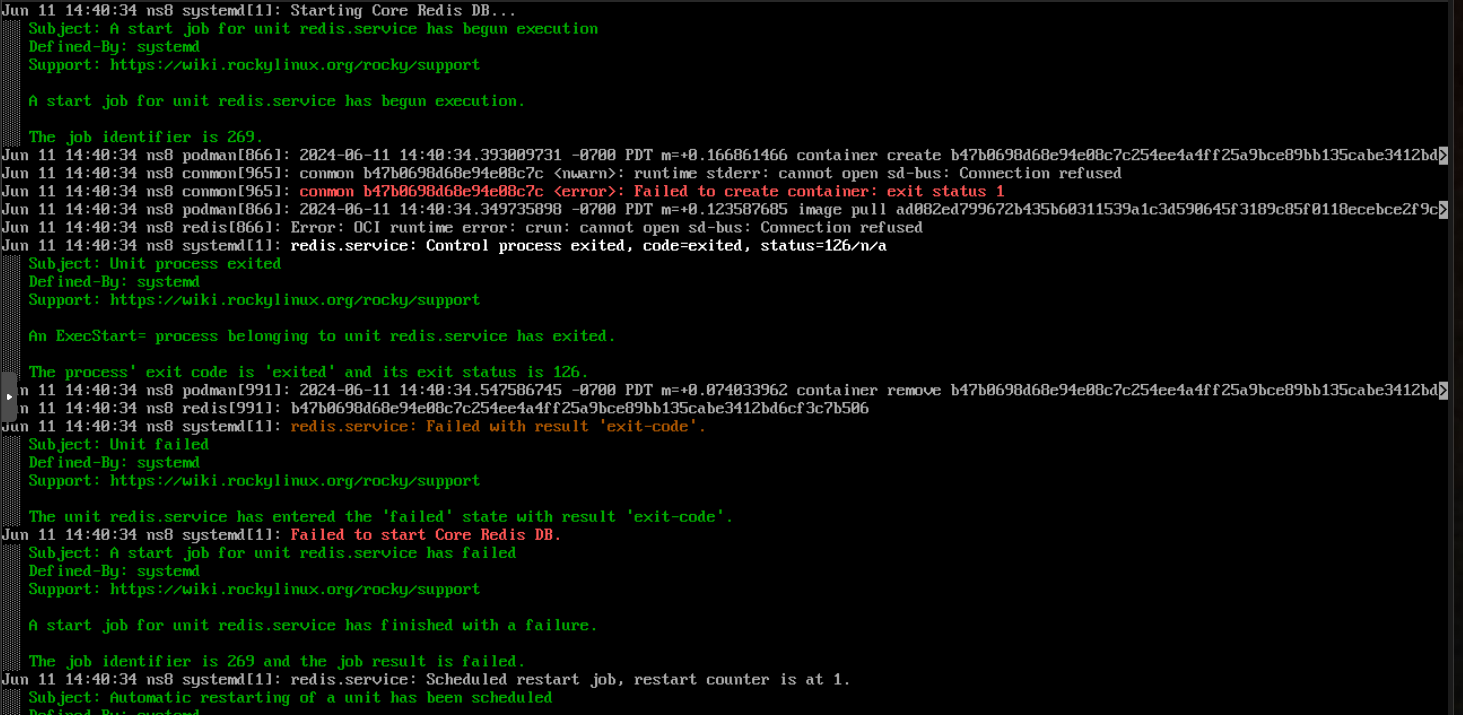
After the reboot of the system nothing is working. None of the services started, no IP was assigned and most importantly, redis fails to start. Here’s the output from the 1st restart attempt:
This also happened in my test system, the main node works, but the secondary one disappeared. The secondary cluster admin tells me to administer on the main one.
I started up another instance of NS8 alongside this broken one, so I could compare the contents of files/directories/systemctl status/etc. as I worked through those references to see if any were relevant. Unfortunately nothing helped and I was back to square one, so started scouring/comparing the logs of the startup of both machines. Digging deeper into one of the permission denied errors on /etc/chrony.keys it really didn’t make any sense at all until I spotted that /etc only had permissions at the owner level of root. The group and other permissions were both NONE. No wonder that hardly anything was working.
Setting those to the normal read/execute got me a lot further, but that showed that the /etc/nethserver directory had been similarly crippled to root only at the owner level. I hoped correcting this would be the final fix, but no.
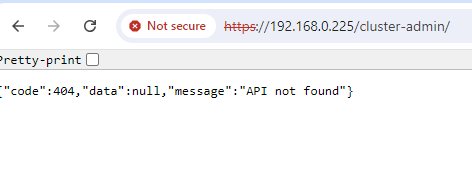
Now, I have this trying to access the UI:
So, what’s my next step here. Have I got another crippled directory, and how did /etc and /etc/nethserver end up with the permissions they had.
Extrapolating the premise that there still might be more directories with blown permissions I ran a couple of “find” jobs on the 2 servers looking for directories with 700 permissions and then compared results. This threw up a few more that needed fixing on the dead upgraded server: