Hi there, I’m reopening this thread because the same “problem” still exist in NS8 and can’t find a way to use the learn_ham feature since the rspamc command doesn’t live in the same container as the Maildir folder. Anybody can help ?
Txs
PS : this means that basically the bayesian filter doesn’t work for anybody that don’t apply this trick.. Just sayin’…
The manual doesn’t state this explicitly, but the behavior mirrors NS7: moving a message into the IMAP Junk folder trains rspamc to recognize it as spam.
Conversely, moving a message to any other folder (except Trash) trains it as ham.
This is the standard training method. For bulk training, you can move multiple messages to the Junk folder using an IMAP client.
You can access the Rspamd UI to check how many messages are learnt so far.
If you prefer a command-line approach, the rspamc program is available in the Dovecot container. It can be executed conveniently with a wrapper script that handles the authentication header. For example, you can use the following command to see available options:
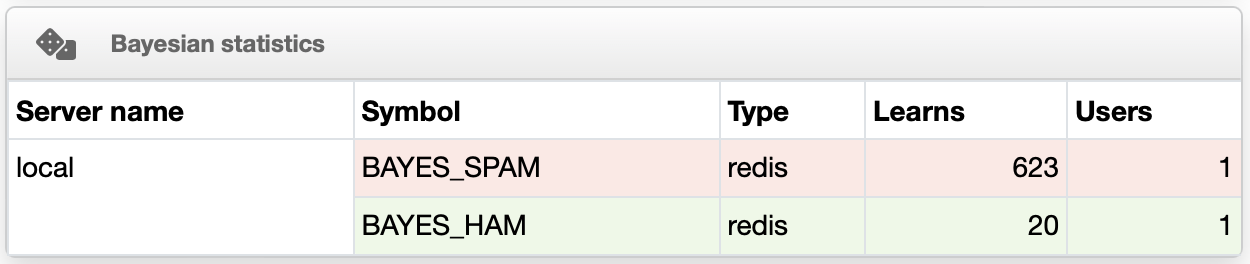
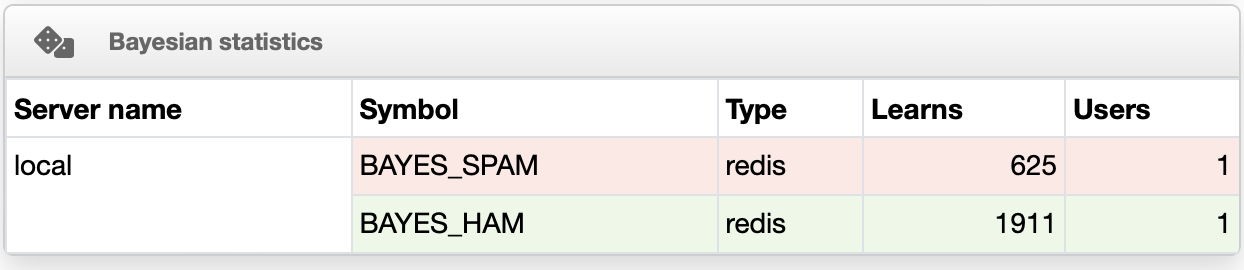
But first and foremost : the Bayesian filter doesn’t work provided there are 200 spams learned. That’s not enough, it’ a common mistake I already emphasised 6 years ago : rspamd needs 200 spams AND 200 hams, as it states clearly in the logs :
2024-12-09T21:43:38+01:00 [1:mail1:rspamd] (normal) <c4538d>; task; bayes_classify: not classified as ham. The ham class needs more training samples. Currently: 20; minimum 200 required
That’s not explained in the documentation, and the UI is quite misleading.
I tried to move email from Inbox to a test folder, and also put them back ib the Inbox folder : that didn’t worked. I believe that only the mails moved out of the Spam folder are learned as ham.
Thanks for the proposed command line. However I don’t know how to specify the path to the /vmail folder where my Inbox resides. Not sure either if or how @Capote 's proposition using redis can help.
Why do you document some aspects into GitHub an others in the regular documentation ? Moreover there is no mention of GitHub into the main one as far as I know.
I hope you agree with me that this is quite an advanced use case. Normally, spam training is performed using the procedure documented on the Mail page of the Admin’s Manual.
If we feel that bulk training should be available to everyone, we would implement a UI-based procedure. For now, since the documented commands are useful for both developers and sysadmins, I’ve opted for the existing resource, the Dev’s README, because bulk training is sometimes necessary during development and QA. Alternatively, we could start a new page under the Admin’s Manual “Best Practices” section with the same information.
In any case, the important thing is that documentation exists!
Actually it is needed as soon a you deploy a mail server since the bayesian filter (without which rspamd’s performance is poor) will not work until 400 false positive are put back into the inbox (which basically will never happen).
So, yes a simple button to let the filter train on real user data would be more than useful.
Depends. The way of doing it is complex, but the task is pretty basic and a routine task when deploying a mail server…
In my view the README in GitHub contains general informations and some instructions regarding the deployment of the software. Not a place to document the way it works. Therefore a Admin’s Manual “Best Practices” or “Tip and tricks” section looks the way to go for me.