Got this in my mailbox this morning:

What are the conditions for thinking a node is offline.
I’m running NS8 in an ESXi VM which is not showing any evidence of being underpowered or resource constrained.
Got this in my mailbox this morning:
What are the conditions for thinking a node is offline.
I’m running NS8 in an ESXi VM which is not showing any evidence of being underpowered or resource constrained.
Do you run more nodes? It seems that just node 1 is affected.
The node agents communicate with the API server via the redis database and if there’s no answer from a node after some attempts it is considered offline.
To check the cluster status from CLI:
api-cli run cluster/get-cluster-status | jq
Maybe it helps to restart the metrics or loki services?
Metrics:
runagent -m metrics1 systemctl --user restart prometheus.service alertmanager.service alert-proxy.service
Loki:
runagent -m loki1 systemctl --user restart loki.service
Please also check the logs for errors, maybe there’s more information about the cause.
I only run a single node.
It happened again yesterday, so I took at look at the logs for loki as that was one of the apps reported and found this at the time of the alert:
2025-06-15T17:19:25-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T00:19:12.349099965Z caller=ring_watcher.go:56 component=frontend-scheduler-worker msg="error getting addresses from ring" err="at least 1 healthy replica required, could only find 0 - unhealthy instances: 127.0.0.1:9095"
2025-06-15T17:19:25-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T00:19:12.609529389Z caller=ring_watcher.go:56 component=querier component=querier-scheduler-worker msg="error getting addresses from ring" err="at least 1 healthy replica required, could only find 0 - unhealthy instances: 127.0.0.1:9095"
2025-06-15T17:19:25-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T00:19:14.269250095Z caller=scheduler.go:635 msg="failed to query the ring to see if scheduler instance is in ReplicatonSet, will try again" err="at least 1 healthy replica required, could only find 0 - unhealthy instances: 127.0.0.1:9095"
2025-06-15T17:19:25-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T00:19:14.29581608Z caller=compactor.go:481 msg="error asking ring for who should run the compactor, will check again" err="at least 1 healthy replica required, could only find 0 - unhealthy instances: 127.0.0.1:9095"
2025-06-15T17:19:25-07:00 [1:loki1:loki-server] level=warn ts=2025-06-16T00:19:22.232885537Z caller=logging.go:102 trace_id_unsampled=0157009625588e56 orgID=fake msg="GET /metrics 741.029858ms, error: write tcp 127.0.0.1:3100->127.0.0.1:49654: write: broken pipe ws: false; Accept: application/openmetrics-text;version=1.0.0;escaping=allow-utf-8;q=0.6,application/openmetrics-text;version=0.0.1;escaping=allow-utf-8;q=0.5,text/plain;version=1.0.0;escaping=allow-utf-8;q=0.4,text/plain;version=0.0.4;escaping=allow-utf-8;q=0.3,*/*;q=0.2; Accept-Encoding: gzip; User-Agent: Prometheus/3.3.1; X-Forwarded-For: 10.0.2.100; X-Forwarded-Host: 10.5.4.1:20009; X-Forwarded-Port: 20009; X-Forwarded-Proto: http; X-Forwarded-Server: loki; X-Prometheus-Scrape-Timeout-Seconds: 10; X-Real-Ip: 10.0.2.100; "
2025-06-15T17:19:36-07:00 [1:loki1:loki-server] level=warn ts=2025-06-16T00:19:36.788179441Z caller=pool.go:250 component=distributor msg="removing ingester failing healthcheck" addr=127.0.0.1:9095 reason="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T17:19:38-07:00 [1:loki1:loki-server] level=warn ts=2025-06-16T00:19:38.032805078Z caller=logging.go:128 trace_id_unsampled=611b5ecd7a125941 orgID=fake msg="POST /loki/api/v1/push (500) 8.366873776s Response: \"rpc error: code = DeadlineExceeded desc = context deadline exceeded\\n\" ws: false; Accept-Encoding: gzip; Content-Length: 15825; Content-Type: application/x-protobuf; User-Agent: Alloy/v1.8.3 (linux; docker); X-Agent-Id: b7df12de-8ea0-48b0-b863-b70eb4f42b99; X-Alloy-Id: b7df12de-8ea0-48b0-b863-b70eb4f42b99; X-Forwarded-For: 10.0.2.100; X-Forwarded-Host: 10.5.4.1:20009; X-Forwarded-Port: 20009; X-Forwarded-Proto: http; X-Forwarded-Server: loki; X-Real-Ip: 10.0.2.100; "
2025-06-15T17:22:22-07:00 [1:loki1:loki-server] level=warn ts=2025-06-16T00:22:22.194285167Z caller=logging.go:102 trace_id_unsampled=7ceec789965e279d orgID=fake msg="GET /metrics 9.938672295s, error: write tcp 127.0.0.1:3100->127.0.0.1:58950: write: broken pipe ws: false; Accept: application/openmetrics-text;version=1.0.0;escaping=allow-utf-8;q=0.6,application/openmetrics-text;version=0.0.1;escaping=allow-utf-8;q=0.5,text/plain;version=1.0.0;escaping=allow-utf-8;q=0.4,text/plain;version=0.0.4;escaping=allow-utf-8;q=0.3,*/*;q=0.2; Accept-Encoding: gzip; User-Agent: Prometheus/3.3.1; X-Forwarded-For: 10.0.2.100; X-Forwarded-Host: 10.5.4.1:20009; X-Forwarded-Port: 20009; X-Forwarded-Proto: http; X-Forwarded-Server: loki; X-Prometheus-Scrape-Timeout-Seconds: 10; X-Real-Ip: 10.0.2.100; "
2025-06-15T17:33:38-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T00:33:38.337473534Z caller=manager.go:50 component=distributor path=write msg="write operation failed" details="couldn't parse push request: read tcp 127.0.0.1:3100->127.0.0.1:45226: i/o timeout" org_id=fake
2025-06-15T17:34:42-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T00:34:42.629128925Z caller=manager.go:50 component=distributor path=write msg="write operation failed" details="couldn't parse push request: unexpected EOF" org_id=fake
2025-06-15T17:34:55-07:00 [1:loki1:loki-server] level=warn ts=2025-06-16T00:34:55.603599446Z caller=logging.go:128 trace_id_unsampled=331bae4e5fd973ff orgID=fake msg="POST /loki/api/v1/push (500) 9.991769321s Response: \"context canceled\\n\" ws: false; Accept-Encoding: gzip; Content-Length: 7769; Content-Type: application/x-protobuf; User-Agent: Alloy/v1.8.3 (linux; docker); X-Agent-Id: b7df12de-8ea0-48b0-b863-b70eb4f42b99; X-Alloy-Id: b7df12de-8ea0-48b0-b863-b70eb4f42b99; X-Forwarded-For: 10.0.2.100; X-Forwarded-Host: 10.5.4.1:20009; X-Forwarded-Port: 20009; X-Forwarded-Proto: http; X-Forwarded-Server: loki; X-Real-Ip: 10.0.2.100; "
2025-06-15T17:35:01-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T00:35:01.907842265Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T17:36:02-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T00:36:02.759188683Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T17:38:27-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T00:38:27.81355896Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T17:52:56-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T00:52:55.981374704Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T17:55:42-07:00 [1:loki1:loki-server] level=warn ts=2025-06-16T00:55:41.993023962Z caller=logging.go:102 trace_id_unsampled=4a96c30a17988cde orgID=fake msg="GET /metrics 41.649354203s, error: write tcp 127.0.0.1:3100->127.0.0.1:46122: i/o timeout ws: false; Accept: application/openmetrics-text;version=1.0.0;escaping=allow-utf-8;q=0.6,application/openmetrics-text;version=0.0.1;escaping=allow-utf-8;q=0.5,text/plain;version=1.0.0;escaping=allow-utf-8;q=0.4,text/plain;version=0.0.4;escaping=allow-utf-8;q=0.3,*/*;q=0.2; Accept-Encoding: gzip; User-Agent: Prometheus/3.3.1; X-Forwarded-For: 10.0.2.100; X-Forwarded-Host: 10.5.4.1:20009; X-Forwarded-Port: 20009; X-Forwarded-Proto: http; X-Forwarded-Server: loki; X-Prometheus-Scrape-Timeout-Seconds: 10; X-Real-Ip: 10.0.2.100; "
2025-06-15T17:55:42-07:00 [1:loki1:loki-server] level=warn ts=2025-06-16T00:55:40.475634053Z caller=logging.go:128 trace_id_unsampled=03a1be097fc9de5a orgID=fake msg="POST /loki/api/v1/push (500) 12.740282013s Response: \"context canceled\\n\" ws: false; Accept-Encoding: gzip; Content-Length: 1668; Content-Type: application/x-protobuf; User-Agent: Alloy/v1.8.3 (linux; docker); X-Agent-Id: b7df12de-8ea0-48b0-b863-b70eb4f42b99; X-Alloy-Id: b7df12de-8ea0-48b0-b863-b70eb4f42b99; X-Forwarded-For: 10.0.2.100; X-Forwarded-Host: 10.5.4.1:20009; X-Forwarded-Port: 20009; X-Forwarded-Proto: http; X-Forwarded-Server: loki; X-Real-Ip: 10.0.2.100; "
2025-06-15T18:17:22-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:17:22.569913755Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T18:18:11-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:17:23.753413342Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T18:18:11-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:17:24.937510564Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T18:18:11-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:17:26.121499584Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T18:18:11-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:17:27.305971546Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T18:18:11-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:17:28.489093781Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T18:18:11-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:17:29.673424055Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T18:18:11-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:17:30.85732473Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T18:18:11-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:17:32.041747925Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T18:18:12-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:18:11.145487436Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T18:18:13-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:18:13.864701424Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = context deadline exceeded"
2025-06-15T18:18:14-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:18:14.365671543Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = received context error while waiting for new LB policy update: context deadline exceeded"
2025-06-15T18:18:14-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:18:14.866726459Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = received context error while waiting for new LB policy update: context deadline exceeded"
2025-06-15T18:18:15-07:00 [1:loki1:loki-server] level=error ts=2025-06-16T01:18:15.845297723Z caller=ratestore.go:303 msg="unable to get stream rates from ingester" ingester=127.0.0.1:9095 err="rpc error: code = DeadlineExceeded desc = received context error while waiting for new LB policy update: context deadline exceeded"
2025-06-15T21:19:22-07:00 [1:loki1:loki-server] level=warn ts=2025-06-16T04:19:21.498911172Z caller=logging.go:102 trace_id_unsampled=55d4732fb1d15f3c orgID=fake msg="GET /metrics 23.044571413s, error: write tcp 127.0.0.1:3100->127.0.0.1:57380: write: broken pipe ws: false; Accept: application/openmetrics-text;version=1.0.0;escaping=allow-utf-8;q=0.6,application/openmetrics-text;version=0.0.1;escaping=allow-utf-8;q=0.5,text/plain;version=1.0.0;escaping=allow-utf-8;q=0.4,text/plain;version=0.0.4;escaping=allow-utf-8;q=0.3,*/*;q=0.2; Accept-Encoding: gzip; User-Agent: Prometheus/3.3.1; X-Forwarded-For: 10.0.2.100; X-Forwarded-Host: 10.5.4.1:20009; X-Forwarded-Port: 20009; X-Forwarded-Proto: http; X-Forwarded-Server: loki; X-Prometheus-Scrape-Timeout-Seconds: 10; X-Real-Ip: 10.0.2.100; "
Metrics reported this app offline at 17:19 and back online at 17:24.
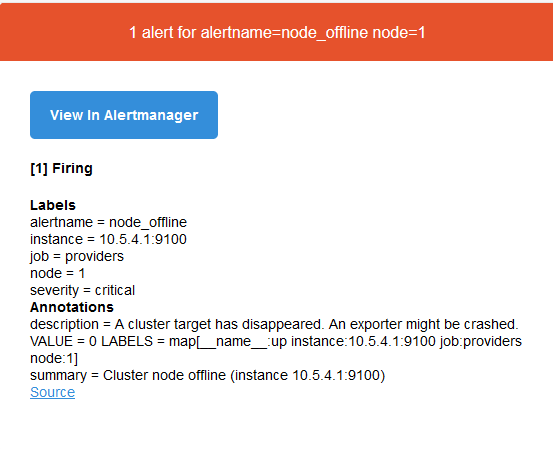
I follow that it’s loki offline when it tells me that app, but what app is it reporting here:
And what is supposed to be displayed if I hit the “View in Alertmanager” as I get this:
Cheers.
On the nodes node_exporters are running to get the information of the node, see Metrics and alerts — NS8 documentation
If a node_exporter isn’t reachable, the alert is fired.
Maybe it helps to restart the node_exporter?
systemctl restart node_exporter
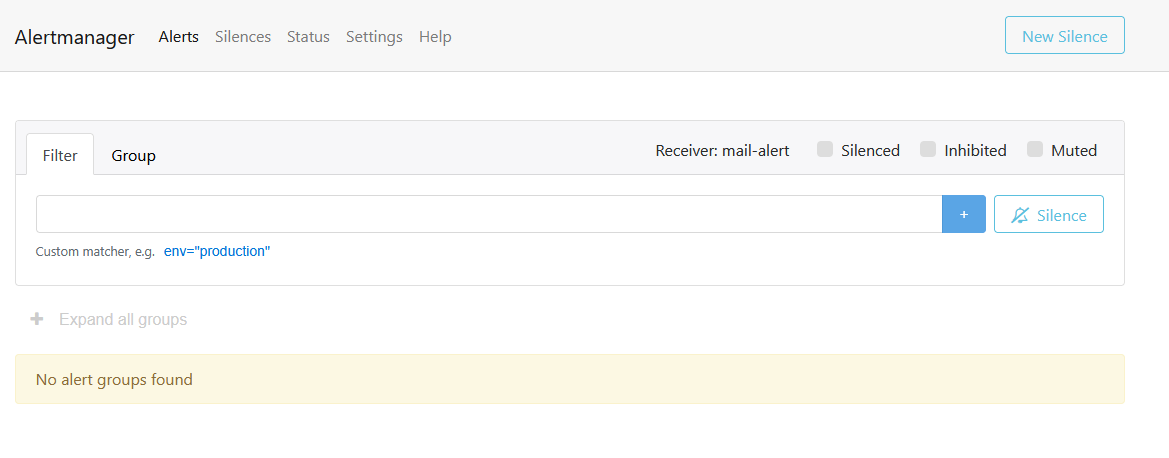
Usually the alert(s) should be shown:
Did you already try to hard refresh the browser or click on “Alerts”?
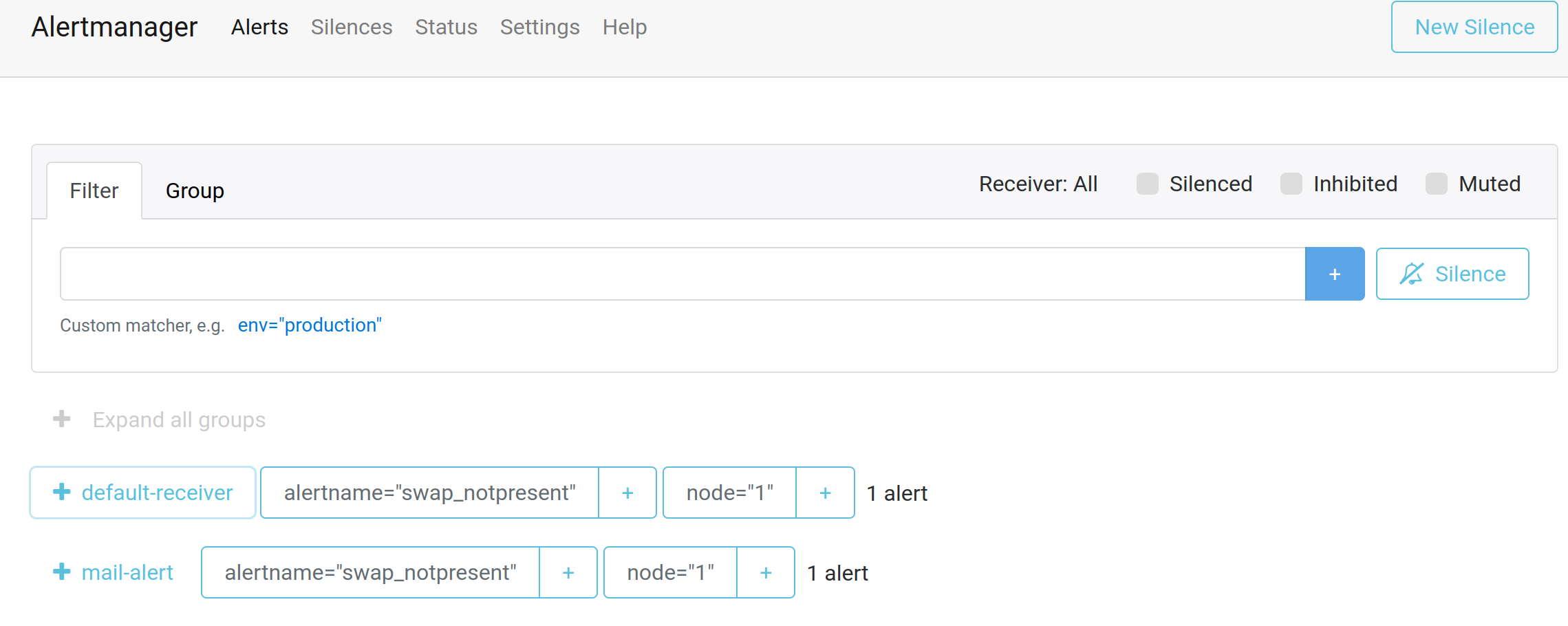
All of the alerts I see are pairs, offline followed 5 minutes later by online. So nothing is staying offline for any length of time.
Same result.
I also copied the link from the mail and opened it in a different browser. Same result.
Cheers.
As the connection is local we can exclude network issues.
I’d investigate again the system and resources load, by the hypervisor side and the VM side, with the core Grafana instance, or with the Netdata app.
You might also search the journal if Promethus scrape times out:
journalctl --grep timeout