something is going wrong on my Nethserver installation I can not explain: Suddenly - without any changes to my System besides regular updates - the system starts not to recognize users within SoGO and - at least - Nextcloud. Let me describe in other words:
when I came back with my family from a forest walk, all mobile devices (iPhones) report a wrong password. When logging onto a Webbrowser on SoGO, It was not possible to login. Same behavior found for Nextcloud. Using 3rd party software relying on AD, login was still possible (Windows domain login was fine as well as some other client software using LDAP).
However, a Nethserver reboot solved the problem temporary, so I was able to login to SoGO Webfrontend. So I decided do delete iPhone Accounts and re-setup without any success. Back on a Browser Login on SoGo was not possible anymore and could be reinitialized after Nethserver reboot.
what is your ldap provider, openldap or samba AD. I am not in front your terminal but I guess a LDAP issue, you could install roundcubemail to workaround the problem, it uses IMAP to authenticate.
Happy Easter! …
I use local AD (samba of course). However other services using Nethserver Bind DN / Base DN, URI, Bind Password work fine using Netherver.
And absolutely strange to me is that the miss-behaviour of nethserver is removed after reboot and it begins approx. after 30 min of operation after reboot / restart …
The 30 min problem makes me think of DNS / PI-Hole…
Do you have a PI-Hole in your Network?
Is your NethServer your DNS? What is your NethServer using as DNS, itself and upstream DNS like Provider / Google?
I did not stop the time how long it takes after reboot, so do not relay on exactly 30 min
To be hones: I do not know, what a PI-Hole is, but I will google it after this response.
Yes, NethServer is my DNS and Nethserver uses my providers DNS (2x), while DHCP provides Nethservers AD DNS (primary) and Nethserver itself (secondary). But the problem even occurs for systems outside my network, e.g. if I use iPhone Mail using G4 network instead of WLAN.
Strange is that the problem startet to occour yesterday somewhere in the afternoon (while I was not even at home and after the system was running stable many weeks). Nextcloud does not allow to check login:
Internal Server Error
The server encountered an internal error and was unable to complete your request.
Please contact the server administrator if this error reappears multiple times, please include the technical details below in your report.
More details can be found in the server log.
While SoGO reports a Login Error. May this have something todo with the PHP update yesterday?
A PI-Hole is a Raspberry PI based (can run on any linux, even VMs…) which is basically a DNS Blackhole for Advertisers or Trackers.
I see often that people using that forget to set DNS correctly on their Servers, NAS (They musn’t use the PI-Hole) and / or the PI-Hole itself (Must have fixed IP, and reliable DNS, like your NethServer or Google…).
When rebooted, and it kicks in, that’s often when problems occurs.
That’s what made me think…
But, correctly configured, both NethServer and PI-Hole work well together. I have both at home running as VM / Container in Proxmox.
Please find the Logs as attached - there seems to be a contact error as you already supposed. But why does the error occour say approx 30 min after reboot, while the first 30 min are fine.?
I counterchecked the changes I remember within the last 10 days:
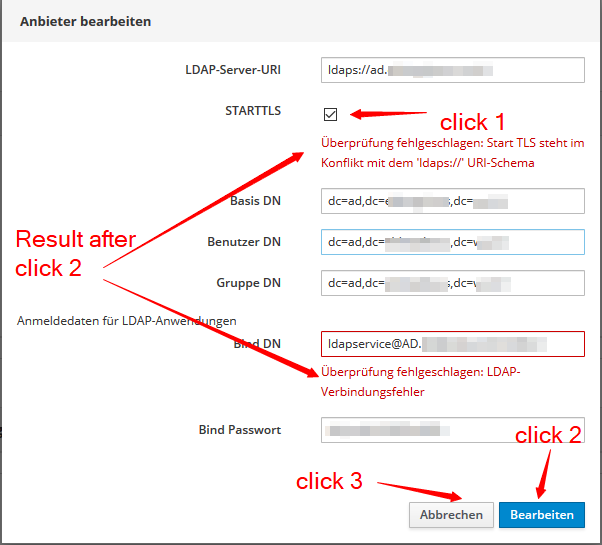
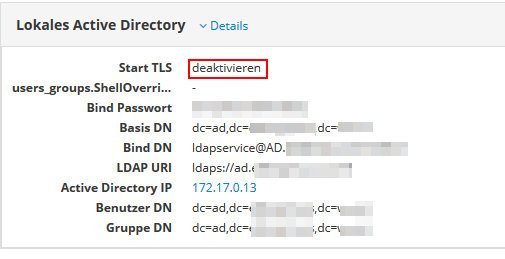
Here I got something strange: A few days (maby two or three weeks) ago, I tried to activate TLS on LDAP, but it did not work (see click-Sequence). I thougth, Nethserver did not accept any changes.
Counterchecking today it reads “Start TLS deaktivate” makeing me think it is active (but that seems to be a translation error on the web interface).
Additionally, I installed an eJabberd App on my iPhone, in order to use the ejabberd Server on Nethserver (it is active but not used for several month) but it did not work, too.
TIA
Thorsten
SOGO
Apr 13 09:32:24 sogod [5204]: 172.17.0.230 “GET /SOGo HTTP/1.1” 302 0/0 0.001 - - 0
Apr 13 09:32:24 sogod [5204]: 172.17.0.230 “GET /SOGo/ HTTP/1.1” 200 8925/0 0.013 28839 69% 0
Apr 13 09:32:32 sogod [5204]: <0x0x558aa1893270[LDAPSource]> <NSException: 0x558aa2dd6580> NAME:LDAPException REASON:operation bind failed: Can’t contact LDAP server (0xFFFFFFFF) INFO:{“error_code” = “-1”; login = “samaccountname=thorsten,dc=ad,dc=XXXXX,dc=XXXXX”; }
Apr 13 09:32:35 sogod [5204]: [ERROR] <0x0x558aa18a3f90[LDAPSource]> Could not bind to the LDAP server ldaps://ad.XXXXX.XXXXX (389) using the bind DN: ldapservice@AD.XXXXX.XXXXX
Apr 13 09:32:35 sogod [5204]: [ERROR] <0x0x558aa18a3f90[LDAPSource]> <NSException: 0x558aa27b0820> NAME:LDAPException REASON:operation bind failed: Can’t contact LDAP server (0xFFFFFFFF) INFO:{“error_code” = “-1”; login = “ldapservice@AD.XXXXX.XXXXX”; }
Apr 13 09:32:35 sogod [5204]: SOGoRootPage Login from ‘172.17.0.230’ for user ‘thorsten’ might not have worked - password policy: 65535 grace: -1 expire: -1 bound: 0
Apr 13 09:32:35 sogod [5204]: 172.17.0.230 “POST /SOGo/connect HTTP/1.1” 403 34/70 4.291 - - 0
On Nextcloud, the server is configured to 636, so there should be no problem. I do not think that it is something on SoGO or nextcloud - something happens after a few minutes breaking the link between those software and Nextcloud LDAP.
pointed to the zentyal secondary domain IP which I changed from dynamic to (another) static on. Don’t ask why I set up Zentyal DC as a secondary DC … it can do Radius (Nethserver`s module is under test) and I tried to link both systems together which worked well by linking Zentyal into Nethserver AD Domain - even Computer manangemant was quite simple and easy accessible…
Additionally, I removed the secondary domain controller using phpmyldap by simply deliting it (I hope this was not too early) and took it down. But still, nethserver DNS still points to the old IP xxx.yyy.0.205 (which was the dynamic one). I did not notice this behavior as I did do the change 10 days ago …
Question: how can I flush / remove that IP from host-list / samba AD list whatever … If I can point it back to xxx.yyy.0.13 (my ad.mydomain.tld), everything should be fine, again.