Yes, it seems so:
journalctl -f
an 14 12:46:59 mdol-nethserver systemd[969]: rspamd.service: Scheduled restart job, restart counter is at 7.
Jan 14 12:46:59 mdol-nethserver systemd[969]: postfix.service: Scheduled restart job, restart counter is at 11.
Jan 14 12:46:59 mdol-nethserver systemd[969]: Stopped postfix.service - Postfix MTA/MSA server.
Jan 14 12:46:59 mdol-nethserver systemd[969]: postfix.service: Consumed 1.767s CPU time.
Jan 14 12:46:59 mdol-nethserver systemd[969]: Starting postfix.service - Postfix MTA/MSA server...
Jan 14 12:46:59 mdol-nethserver systemd[969]: Stopped rspamd.service - Rspamd mail filter.
Jan 14 12:46:59 mdol-nethserver systemd[969]: Starting rspamd.service - Rspamd mail filter...
Jan 14 12:47:00 mdol-nethserver systemd[968]: nextcloud-app.service: start operation timed out. Terminating.
Jan 14 12:47:01 mdol-nethserver traefik[1911]: 164.132.77.214 - - [14/Jan/2025:11:47:01 +0000] "GET /TIME.txt HTTP/1.1" 404 19 "-" "-" 53 "-" "-" 0ms
Jan 14 12:47:06 mdol-nethserver podman[5905]: 2025-01-14 12:46:59.192627172 +0100 CET m=+56.810159702 image pull ghcr.io/nethserver/mail-dovecot:1.5.0
Jan 14 12:47:21 mdol-nethserver podman[5982]: 2025-01-14 12:47:21.40760942 +0100 CET m=+29.734965595 container remove 0b88ce64d04bd8af368d564929985b31c8a2caed7d3caf5884e79252960bb92f (image=localhost/podman-pause:4.3.1-0, name=bd8a7c6a076e-infra, pod_id=bd8a7c6a076e04a9c6cb94dfb71594b02640e2084458e5634382a3a70d02648a, PODMAN_SYSTEMD_UNIT=roundcubemail.service, io.buildah.version=1.28.2)
Jan 14 12:47:21 mdol-nethserver systemd[970]: Removed slice user-libpod_pod_bd8a7c6a076e04a9c6cb94dfb71594b02640e2084458e5634382a3a70d02648a.slice - cgroup user-libpod_pod_bd8a7c6a076e04a9c6cb94dfb71594b02640e2084458e5634382a3a70d02648a.slice.
Jan 14 12:47:21 mdol-nethserver traefik[1911]: 93.244.189.103 - - [14/Jan/2025:11:47:21 +0000] "PROPFIND /remote.php/dav/files/8F8C1AAC-C6AE-44D3-A2E2-7853FDCF0924/ HTTP/1.1" 502 11 "-" "-" 54 "nextcloud2-https@file" "http://127.0.0.1:20008" 187ms
Jan 14 12:47:25 mdol-nethserver systemd[975]: collabora.service: start operation timed out. Terminating.
Jan 14 12:47:29 mdol-nethserver podman[5982]: 2025-01-14 12:47:29.556616472 +0100 CET m=+37.883972707 pod remove bd8a7c6a076e04a9c6cb94dfb71594b02640e2084458e5634382a3a70d02648a (image=, name=roundcubemail)
Jan 14 12:47:29 mdol-nethserver podman[5982]: time="2025-01-14T12:47:29+01:00" level=warning msg="Found incomplete layer \"a5e4051d9f06a301c59fb7be3e9b8d23e4087a709b180cd0ad5eff22d04fe36f\", deleting it"
Jan 14 12:47:31 mdol-nethserver systemd[969]: clamav.service: start operation timed out. Terminating.
Jan 14 12:47:40 mdol-nethserver podman[5995]: 2025-01-14 12:47:40.258496726 +0100 CET m=+47.736820954 container remove 81707d2d724602339596e11323325247aedd6e6afb8eeb368a62b936cf53d3a4 (image=localhost/podman-pause:4.3.1-0, name=e64ac835d844-infra, pod_id=e64ac835d844ce3de1d523f27b51190540f807edf6ee3090ec9ddf869f2721dc, PODMAN_SYSTEMD_UNIT=lamp.service, io.buildah.version=1.28.2)
Jan 14 12:47:40 mdol-nethserver systemd[974]: Removed slice user-libpod_pod_e64ac835d844ce3de1d523f27b51190540f807edf6ee3090ec9ddf869f2721dc.slice - cgroup user-libpod_pod_e64ac835d844ce3de1d523f27b51190540f807edf6ee3090ec9ddf869f2721dc.slice.
Jan 14 12:47:45 mdol-nethserver systemd[970]: Created slice user-libpod_pod_635e5b3a7a8b457fc291b094b5ae86ef72da628d19da15ec49c3f9c516b49221.slice - cgroup user-libpod_pod_635e5b3a7a8b457fc291b094b5ae86ef72da628d19da15ec49c3f9c516b49221.slice.
Jan 14 12:47:47 mdol-nethserver podman[5995]: 2025-01-14 12:47:47.587852619 +0100 CET m=+55.066176867 pod remove e64ac835d844ce3de1d523f27b51190540f807edf6ee3090ec9ddf869f2721dc (image=, name=lamp)
Jan 14 12:47:47 mdol-nethserver systemd[974]: Created slice user-libpod_pod_bfc1b74881ce5116aa88a15a7e97b6335b2a7e4d84ac8fd5a5afcd5d85ab9111.slice - cgroup user-libpod_pod_bfc1b74881ce5116aa88a15a7e97b6335b2a7e4d84ac8fd5a5afcd5d85ab9111.slice.
Jan 14 12:47:47 mdol-nethserver podman[5884]:
Jan 14 12:47:52 mdol-nethserver podman[5884]: 2025-01-14 12:47:52.495793986 +0100 CET m=+111.121994480 container create 7632f1425dd9c58b81ec4d13ad6383a5b1dab6430845cb71174b7b6b66271bd3 (image=ghcr.io/nethserver/mail-clamav:1.5.0, name=clamav, PODMAN_SYSTEMD_UNIT=clamav.service, io.buildah.version=1.23.1)
Jan 14 12:47:55 mdol-nethserver sshd[6099]: error: kex_exchange_identification: Connection closed by remote host
Jan 14 12:47:55 mdol-nethserver sshd[6099]: Connection closed by 203.142.69.146 port 61001
Jan 14 12:48:03 mdol-nethserver traefik[1911]: 93.244.189.103 - - [14/Jan/2025:11:48:03 +0000] "GET / HTTP/1.1" 502 11 "-" "-" 55 "lamp2-https@file" "http://127.0.0.1:20021" 0ms
Jan 14 12:48:04 mdol-nethserver podman[6067]: 2025-01-14 12:48:04.147703518 +0100 CET m=+63.568897694 image pull ghcr.io/nethserver/mail-rspamd:1.5.0
Jan 14 12:48:04 mdol-nethserver podman[6056]: 2025-01-14 12:48:04.148402064 +0100 CET m=+63.952144306 image pull ghcr.io/nethserver/mail-postfix:1.5.0
Jan 14 12:48:08 mdol-nethserver podman[5967]: 2025-01-14 12:48:08.279084953 +0100 CET m=+84.959761707 container remove 8e18a7dd9945d6d069bcdcda8742b1de37809d2ee01eb8615b9a007634aeb351 (image=ghcr.io/nethserver/mail-postfix:1.5.0, name=postfix-import-certificate, io.buildah.version=1.23.1)
Jan 14 12:48:10 mdol-nethserver systemd[968]: nextcloud-app.service: State 'stop-sigterm' timed out. Killing.
Jan 14 12:48:10 mdol-nethserver systemd[968]: nextcloud-app.service: Killing process 5805 (podman) with signal SIGKILL.
Jan 14 12:48:10 mdol-nethserver systemd[968]: nextcloud-app.service: Killing process 5814 (n/a) with signal SIGKILL.
Jan 14 12:48:10 mdol-nethserver systemd[968]: nextcloud-app.service: Killing process 5815 (podman) with signal SIGKILL.
Jan 14 12:48:10 mdol-nethserver systemd[968]: nextcloud-app.service: Killing process 5820 (podman) with signal SIGKILL.
Jan 14 12:48:10 mdol-nethserver systemd[968]: nextcloud-app.service: Killing process 5821 (podman) with signal SIGKILL.
Jan 14 12:48:10 mdol-nethserver systemd[968]: nextcloud-app.service: Killing process 5822 (n/a) with signal SIGKILL.
Jan 14 12:48:10 mdol-nethserver systemd[968]: nextcloud-app.service: Killing process 5921 (n/a) with signal SIGKILL.
Jan 14 12:48:10 mdol-nethserver systemd[968]: nextcloud-app.service: Killing process 6019 (n/a) with signal SIGKILL.
Jan 14 12:48:11 mdol-nethserver systemd[968]: nextcloud-app.service: Control process exited, code=killed, status=9/KILL
Jan 14 12:48:11 mdol-nethserver podman[6109]: Error: reading CIDFile: open /run/user/1003/nextcloud-app.ctr-id: no such file or directory
Jan 14 12:48:11 mdol-nethserver systemd[968]: nextcloud-app.service: Control process exited, code=exited, status=125/n/a
Jan 14 12:48:11 mdol-nethserver systemd[968]: nextcloud-app.service: Failed with result 'timeout'.
Jan 14 12:48:11 mdol-nethserver systemd[968]: Failed to start nextcloud-app.service - Podman nextcloud-app.service.
Jan 14 12:48:11 mdol-nethserver systemd[968]: nextcloud-app.service: Consumed 1.614s CPU time.
Jan 14 12:48:11 mdol-nethserver systemd[968]: Starting nextcloud-nginx.service - Podman nextcloud-nginx.service...
Jan 14 12:48:11 mdol-nethserver podman[6121]: time="2025-01-14T12:48:11+01:00" level=warning msg="Found incomplete layer \"39b574542c1a154cb699b5282e9e75c85f8c4d731f19aed68c67d88bf08487e0\", deleting it"
Jan 14 12:48:12 mdol-nethserver systemd[968]: nextcloud-app.service: Scheduled restart job, restart counter is at 8.
Jan 14 12:48:12 mdol-nethserver systemd[968]: Stopped nextcloud-app.service - Podman nextcloud-app.service.
Jan 14 12:48:12 mdol-nethserver systemd[968]: nextcloud-app.service: Consumed 1.614s CPU time.
Jan 14 12:48:12 mdol-nethserver systemd[968]: Starting nextcloud-app.service - Podman nextcloud-app.service...
Jan 14 12:48:17 mdol-nethserver podman[5995]:
Jan 14 12:48:21 mdol-nethserver systemd[970]: roundcubemail.service: start-pre operation timed out. Terminating.
Jan 14 12:48:22 mdol-nethserver systemd[974]: lamp.service: start-pre operation timed out. Terminating
additional
root@mdol-nethserver:~# journalctl -f
Jan 14 12:55:02 mdol-nethserver systemd[969]: rspamd.service: Consumed 1.363s CPU time.
Jan 14 12:55:21 mdol-nethserver postfix[7041]: enabled
Jan 14 12:55:02 mdol-nethserver systemd[969]: rspamd.service: Scheduled restart job, restart counter is at 10.
Jan 14 12:55:02 mdol-nethserver systemd[969]: Stopped rspamd.service - Rspamd mail filter.
Jan 14 12:55:02 mdol-nethserver systemd[969]: rspamd.service: Consumed 1.363s CPU time.
Jan 14 12:55:02 mdol-nethserver systemd[969]: Starting rspamd.service - Rspamd mail filter...
Jan 14 12:55:05 mdol-nethserver systemd[969]: clamav.service: start operation timed out. Terminating.
Jan 14 12:55:05 mdol-nethserver systemd[969]: postfix.service: start-pre operation timed out. Terminating.
Jan 14 12:55:17 mdol-nethserver podman[6883]: 2025-01-14 12:55:17.286521875 +0100 CET m=+101.529479131 container create cd5f2eb9f0c72ed87903b77fd8934aca1e8859d9e033e7a07d6c1f18b31e6f5a (image=ghcr.io/nethserver/mail-dovecot:1.5.0, name=dovecot-import-certificate, PODMAN_SYSTEMD_UNIT=dovecot.service, io.buildah.version=1.23.1)
Jan 14 12:55:17 mdol-nethserver crowdsec1-firewall-bouncer[4750]: time="2025-01-14T11:55:17Z" level=info msg="72 decisions deleted"
Jan 14 12:55:22 mdol-nethserver podman[6942]: 2025-01-14 12:55:22.363539828 +0100 CET m=+66.991267280 container remove bc66be05e7d90ae20b8f538b3c10e7959f2296bf2cd759106d0f9acd65c6393e (image=localhost/podman-pause:4.3.1-0, name=291faa950d68-infra, pod_id=291faa950d68d59d80bd8fc13396e5645ac856abc12e358f0478ace396f333c1, PODMAN_SYSTEMD_UNIT=roundcubemail.service, io.buildah.version=1.28.2)
Jan 14 12:55:22 mdol-nethserver podman[6958]:
Jan 14 12:55:22 mdol-nethserver systemd[970]: Removed slice user-libpod_pod_291faa950d68d59d80bd8fc13396e5645ac856abc12e358f0478ace396f333c1.slice - cgroup user-libpod_pod_291faa950d68d59d80bd8fc13396e5645ac856abc12e358f0478ace396f333c1.slice.
Jan 14 12:55:22 mdol-nethserver podman[6974]: 2025-01-14 12:54:33.773953901 +0100 CET m=+8.899768886 image pull docker.io/mariadb:10.6.20
Jan 14 12:55:24 mdol-nethserver podman[6958]: 2025-01-14 12:55:24.820013253 +0100 CET m=+60.041937996 container create b0dc2b34ec4ab32d30cc7719327a9f1db32948999cb5b315d4099737d8fc4b6f (image=docker.io/library/nginx:1.27.3-alpine, name=nextcloud-nginx, pod_id=32f2435d3aab31f42dd27e77ce9d377ad2006593d2da93759d5534f77000b36e, PODMAN_SYSTEMD_UNIT=nextcloud-nginx.service, maintainer=NGINX Docker Maintainers <docker-maint@nginx.com>)
Jan 14 12:55:24 mdol-nethserver podman[7011]: 2025-01-14 12:55:24.904309919 +0100 CET m=+50.786982937 container remove 075804ea34f6e5f0478064487eff668151be78ef67332bd7392b64462af971c6 (image=localhost/podman-pause:4.3.1-0, name=bb7f197d5d70-infra, pod_id=bb7f197d5d70f0bf16e51314a19fc18901e855c5b917ad3b709e5297356cbfe8, PODMAN_SYSTEMD_UNIT=lamp.service, io.buildah.version=1.28.2)
Jan 14 12:55:24 mdol-nethserver systemd[974]: Removed slice user-libpod_pod_bb7f197d5d70f0bf16e51314a19fc18901e855c5b917ad3b709e5297356cbfe8.slice - cgroup user-libpod_pod_bb7f197d5d70f0bf16e51314a19fc18901e855c5b917ad3b709e5297356cbfe8.slice.
Jan 14 12:55:25 mdol-nethserver podman[6987]: 2025-01-14 12:54:33.773920676 +0100 CET m=+1.855431899 image pull ghcr.io/nethserver/nextcloud-app:1.3.0
Jan 14 12:55:25 mdol-nethserver postfix[7052]: Error: reading CIDFile: open /run/user/1004/postfix.ctr-id: no such file or directory
Jan 14 12:55:25 mdol-nethserver clamav[7042]: Error: reading CIDFile: open /run/user/1004/clamav.ctr-id: no such file or directory
Jan 14 12:55:25 mdol-nethserver systemd[969]: postfix.service: Control process exited, code=exited, status=125/n/a
Jan 14 12:55:25 mdol-nethserver systemd[969]: clamav.service: Control process exited, code=exited, status=125/n/a
Jan 14 12:55:25 mdol-nethserver systemd[969]: clamav.service: Failed with result 'timeout'.
Jan 14 12:55:25 mdol-nethserver systemd[969]: Failed to start clamav.service - ClamAV anti-virus.
Jan 14 12:55:25 mdol-nethserver systemd[969]: clamav.service: Scheduled restart job, restart counter is at 13.
Jan 14 12:55:25 mdol-nethserver systemd[969]: Stopped clamav.service - ClamAV anti-virus.
Jan 14 12:55:25 mdol-nethserver systemd[969]: Starting clamav.service - ClamAV anti-virus...
Jan 14 12:55:26 mdol-nethserver podman[6942]: 2025-01-14 12:55:26.685270287 +0100 CET m=+71.312997749 pod remove 291faa950d68d59d80bd8fc13396e5645ac856abc12e358f0478ace396f333c1 (image=, name=roundcubemail)
Jan 14 12:55:26 mdol-nethserver systemd[970]: Created slice user-libpod_pod_84de72ae10093b48ef6c1afd2cb8206be96a19eb3a2f3aa4ba241c1d36936951.slice - cgroup user-libpod_pod_84de72ae10093b48ef6c1afd2cb8206be96a19eb3a2f3aa4ba241c1d36936951.slice.
Jan 14 12:55:27 mdol-nethserver crowdsec1-firewall-bouncer[4750]: time="2025-01-14T11:55:27Z" level=info msg="72 decisions deleted"
Jan 14 12:55:28 mdol-nethserver systemd[969]: Started libpod-cd5f2eb9f0c72ed87903b77fd8934aca1e8859d9e033e7a07d6c1f18b31e6f5a.scope - libcrun container.
Jan 14 12:55:29 mdol-nethserver podman[7011]: 2025-01-14 12:55:29.167981158 +0100 CET m=+55.050654176 pod remove bb7f197d5d70f0bf16e51314a19fc18901e855c5b917ad3b709e5297356cbfe8 (image=, name=lamp)
Jan 14 12:55:31 mdol-nethserver systemd[974]: Created slice user-libpod_pod_ceb03367fb6d8ac33fa220ba0be78739cffe5c733c4b88f6748f83f2e572ef6a.slice - cgroup user-libpod_pod_ceb03367fb6d8ac33fa220ba0be78739cffe5c733c4b88f6748f83f2e572ef6a.slice.
Jan 14 12:55:31 mdol-nethserver podman[7028]: 2025-01-14 12:55:25.645812488 +0100 CET m=+21.714753507 image pull ghcr.io/nethserver/mail-rspamd:1.5.0
Jan 14 12:55:31 mdol-nethserver podman[7072]: 2025-01-14 12:55:31.892164854 +0100 CET m=+6.012968375 image pull ghcr.io/nethserver/mail-clamav:1.5.0
Jan 14 12:55:32 mdol-nethserver podman[6883]: 2025-01-14 12:55:32.031544971 +0100 CET m=+116.274502227 container init cd5f2eb9f0c72ed87903b77fd8934aca1e8859d9e033e7a07d6c1f18b31e6f5a (image=ghcr.io/nethserver/mail-dovecot:1.5.0, name=dovecot-import-certificate, PODMAN_SYSTEMD_UNIT=dovecot.service, io.buildah.version=1.23.1)
Jan 14 12:55:33 mdol-nethserver traefik[1911]: 93.244.189.103 - - [14/Jan/2025:11:55:32 +0000] "GET /index.php/204 HTTP/2.0" 502 11 "-" "-" 64 "nextcloud2-https@file" "http://127.0.0.1:20008" 187ms
Jan 14 12:55:33 mdol-nethserver podman[6883]: 2025-01-14 12:55:33.761906463 +0100 CET m=+118.004863719 container start cd5f2eb9f0c72ed87903b77fd8934aca1e8859d9e033e7a07d6c1f18b31e6f5a (image=ghcr.io/nethserver/mail-dovecot:1.5.0, name=dovecot-import-certificate, PODMAN_SYSTEMD_UNIT=dovecot.service, io.buildah.version=1.23.1)
Jan 14 12:55:33 mdol-nethserver podman[6883]: 2025-01-14 12:55:33.762803023 +0100 CET m=+118.005760279 container attach cd5f2eb9f0c72ed87903b77fd8934aca1e8859d9e033e7a07d6c1f18b31e6f5a (image=ghcr.io/nethserver/mail-dovecot:1.5.0, name=dovecot-import-certificate, PODMAN_SYSTEMD_UNIT=dovecot.service, io.buildah.version=1.23.1)
Jan 14 12:55:33 mdol-nethserver podman[6883]: 2025-01-14 12:55:33.770087297 +0100 CET m=+118.013044553 container died cd5f2eb9f0c72ed87903b77fd8934aca1e8859d9e033e7a07d6c1f18b31e6f5a (image=ghcr.io/nethserver/mail-dovecot:1.5.0, name=dovecot-import-certificate, io.buildah.version=1.23.1, PODMAN_SYSTEMD_UNIT=dovecot.service)
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: State 'stop-sigterm' timed out. Killing.
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Killing process 6769 (podman) with signal SIGKILL.
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Killing process 6772 (podman) with signal SIGKILL.
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Killing process 6773 (podman) with signal SIGKILL.
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Killing process 6774 (podman) with signal SIGKILL.
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Killing process 6775 (n/a) with signal SIGKILL.
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Killing process 6776 (podman) with signal SIGKILL.
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Killing process 6777 (n/a) with signal SIGKILL.
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Killing process 6779 (n/a) with signal SIGKILL.
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Killing process 6780 (n/a) with signal SIGKILL.
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Killing process 6927 (podman) with signal SIGKILL.
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Control process exited, code=killed, status=9/KILL
Jan 14 12:55:34 mdol-nethserver collabora2[7105]: Error: reading CIDFile: open /run/user/1012/collabora.ctr-id: no such file or directory
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Control process exited, code=exited, status=125/n/a
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Failed with result 'timeout'.
Jan 14 12:55:34 mdol-nethserver systemd[975]: Failed to start collabora.service - Podman collabora.service.
Jan 14 12:55:34 mdol-nethserver systemd[975]: collabora.service: Consumed 2.500s CPU time.
Jan 14 12:55:35 mdol-nethserver systemd[975]: collabora.service: Scheduled restart job, restart counter is at 12.
Jan 14 12:55:35 mdol-nethserver systemd[975]: Stopped collabora.service - Podman collabora.service.
Jan 14 12:55:35 mdol-nethserver systemd[975]: collabora.service: Consumed 2.500s CPU time.
Jan 14 12:55:35 mdol-nethserver systemd[975]: Starting collabora.service - Podman collabora.service...
Jan 14 12:55:35 mdol-nethserver collabora2[7117]: time="2025-01-14T12:55:35+01:00" level=warning msg="Found incomplete layer \"a942df84c1ee840421d8cd01c5e40d157e03ba4a3b225a93379a8b559df97313\", deleting it"
Jan 14 12:55:37 mdol-nethserver systemd[968]: Started libpod-b0dc2b34ec4ab32d30cc7719327a9f1db32948999cb5b315d4099737d8fc4b6f.scope - libcrun container.
Jan 14 12:55:40 mdol-nethserver podman[6958]: 2025-01-14 12:55:40.165535341 +0100 CET m=+75.387460154 container init b0dc2b34ec4ab32d30cc7719327a9f1db32948999cb5b315d4099737d8fc4b6f (image=docker.io/library/nginx:1.27.3-alpine, name=nextcloud-nginx, pod_id=32f2435d3aab31f42dd27e77ce9d377ad2006593d2da93759d5534f77000b36e, PODMAN_SYSTEMD_UNIT=nextcloud-nginx.service, maintainer=NGINX Docker Maintainers <docker-maint@nginx.com>)
Jan 14 12:55:40 mdol-nethserver nextcloud-nginx[7133]: /docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
Jan 14 12:55:40 mdol-nethserver nextcloud-nginx[7133]: /docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
Jan 14 12:55:40 mdol-nethserver nextcloud-nginx[7133]: /docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
Jan 14 12:55:40 mdol-nethserver nextcloud-nginx[7133]: 10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf
Jan 14 12:55:41 mdol-nethserver traefik[1911]: 68.183.200.200 - - [14/Jan/2025:11:55:41 +0000] "GET / HTTP/1.1" 404 19 "-" "-" 65 "-" "-" 0ms
Jan 14 12:55:41 mdol-nethserver traefik[1911]: 68.183.200.200 - - [14/Jan/2025:11:55:41 +0000] "GET /favicon.ico HTTP/1.1" 404 19 "-" "-" 66 "-" "-" 0ms
Jan 14 12:55:42 mdol-nethserver traefik[1911]: 68.183.200.200 - - [14/Jan/2025:11:55:42 +0000] "GET /ads.txt HTTP/1.1" 404 19 "-" "-" 67 "-" "-" 0ms
Jan 14 12:55:42 mdol-nethserver podman[6942]:
Jan 14 12:55:42 mdol-nethserver podman[6958]: 2025-01-14 12:55:42.292455991 +0100 CET m=+77.514380764 container start b0dc2b34ec4ab32d30cc7719327a9f1db32948999cb5b315d4099737d8fc4b6f (image=docker.io/library/nginx:1.27.3-alpine, name=nextcloud-nginx, pod_id=32f2435d3aab31f42dd27e77ce9d377ad2006593d2da93759d5534f77000b36e, PODMAN_SYSTEMD_UNIT=nextcloud-nginx.service, maintainer=NGINX Docker Maintainers <docker-maint@nginx.com>)
Jan 14 12:55:42 mdol-nethserver podman[6958]: b0dc2b34ec4ab32d30cc7719327a9f1db32948999cb5b315d4099737d8fc4b6f
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: /docker-entrypoint.sh: Sourcing /docker-entrypoint.d/15-local-resolvers.envsh
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: /docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: /docker-entrypoint.sh: Launching /docker-entrypoint.d/30-tune-worker-processes.sh
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: /docker-entrypoint.sh: Configuration complete; ready for start up
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 2025/01/14 11:55:42 [notice] 1#1: using the "epoll" event method
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 2025/01/14 11:55:42 [notice] 1#1: nginx/1.27.3
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 2025/01/14 11:55:42 [notice] 1#1: built by gcc 13.2.1 20240309 (Alpine 13.2.1_git20240309)
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 2025/01/14 11:55:42 [notice] 1#1: OS: Linux 6.1.0-25-amd64
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 2025/01/14 11:55:42 [notice] 1#1: getrlimit(RLIMIT_NOFILE): 1048576:1048576
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 2025/01/14 11:55:42 [notice] 1#1: start worker processes
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 2025/01/14 11:55:42 [notice] 1#1: start worker process 25
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 2025/01/14 11:55:42 [notice] 1#1: start worker process 26
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 2025/01/14 11:55:42 [notice] 1#1: start worker process 27
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 2025/01/14 11:55:42 [notice] 1#1: start worker process 28
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 2025/01/14 11:55:42 [notice] 1#1: start worker process 29
Jan 14 12:55:42 mdol-nethserver nextcloud-nginx[7133]: 2025/01/14 11:55:42 [notice] 1#1: start worker process 30
Jan 14 12:55:43 mdol-nethserver traefik[1911]: 68.183.200.200 - - [14/Jan/2025:11:55:43 +0000] "GET / HTTP/1.1" 404 19 "-" "-" 68 "-" "-" 0ms
Jan 14 12:55:44 mdol-nethserver podman[6942]: 2025-01-14 12:55:44.739713963 +0100 CET m=+89.367441425 container create 477bfe7cb912ff8ef6af17847d9307836de690f639513e64ef4df1b4da5d03ed (image=localhost/podman-pause:4.3.1-0, name=84de72ae1009-infra, pod_id=84de72ae10093b48ef6c1afd2cb8206be96a19eb3a2f3aa4ba241c1d36936951, io.buildah.version=1.28.2, PODMAN_SYSTEMD_UNIT=roundcubemail.service)
Jan 14 12:55:45 mdol-nethserver systemd[970]: roundcubemail.service: start-pre operation timed out. Terminating.
Jan 14 12:55:46 mdol-nethserver podman[7011]:
Jan 14 12:55:46 mdol-nethserver podman[7167]: Error: name or ID cannot be empty
Jan 14 12:55:46 mdol-nethserver systemd[970]: roundcubemail.service: Control process exited, code=exited, status=125/n/a
Jan 14 12:55:46 mdol-nethserver systemd[970]: roundcubemail.service: Failed with result 'timeout'.
Jan 14 12:55:46 mdol-nethserver systemd[970]: Failed to start roundcubemail.service - Podman roundcubemail.service.
Jan 14 12:55:46 mdol-nethserver systemd[970]: Dependency failed for roundcubemail-app.service - Podman roundcubemail-app.service.
Jan 14 12:55:46 mdol-nethserver systemd[970]: roundcubemail-app.service: Job roundcubemail-app.service/start failed with result 'dependency'.
Jan 14 12:55:46 mdol-nethserver systemd[970]: Dependency failed for mariadb-app.service - Podman mariadb-app.service.
Jan 14 12:55:46 mdol-nethserver systemd[970]: mariadb-app.service: Job mariadb-app.service/start failed with result 'dependency'.
Jan 14 12:55:46 mdol-nethserver systemd[970]: roundcubemail.service: Scheduled restart job, restart counter is at 5.
Jan 14 12:55:46 mdol-nethserver systemd[970]: Stopped roundcubemail.service - Podman roundcubemail.service.
Jan 14 12:55:46 mdol-nethserver systemd[970]: Starting roundcubemail.service - Podman roundcubemail.service...
Jan 14 12:55:48 mdol-nethserver podman[7011]: 2025-01-14 12:55:48.208727147 +0100 CET m=+74.091400165 container create 168a70358434b708b475380bfabfaca40977eb52c18e8d36a42cb2ee77adafd6 (image=localhost/podman-pause:4.3.1-0, name=ceb03367fb6d-infra, pod_id=ceb03367fb6d8ac33fa220ba0be78739cffe5c733c4b88f6748f83f2e572ef6a, PODMAN_SYSTEMD_UNIT=lamp.service, io.buildah.version=1.28.2)
Jan 14 12:55:49 mdol-nethserver podman[7117]: 2025-01-14 12:55:35.16966014 +0100 CET m=+0.022632379 image pull docker.io/collabora/code:24.04.7.1.2
BTW what is the error here?
There is no output. Maybe I have confused a missing output with an error.
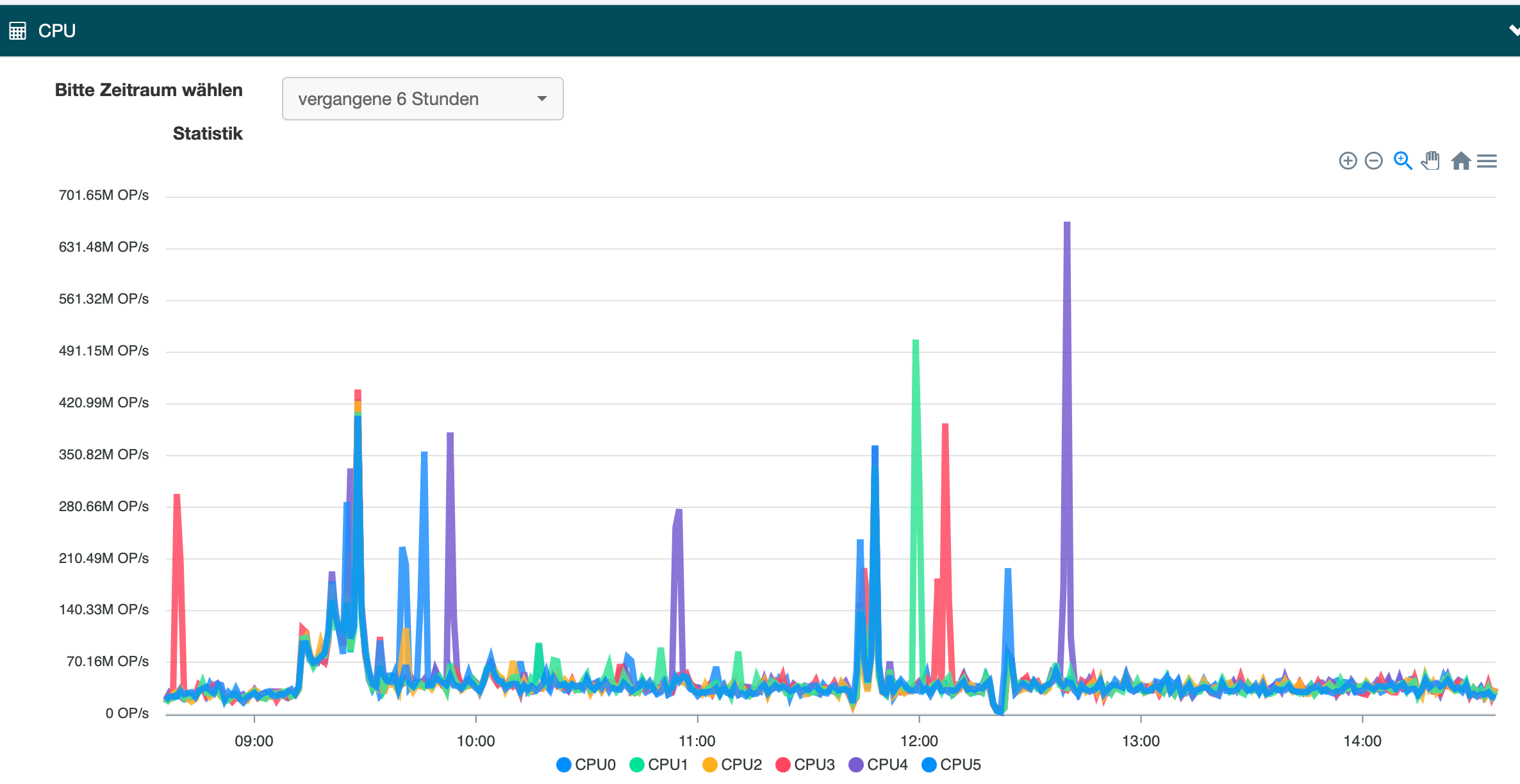
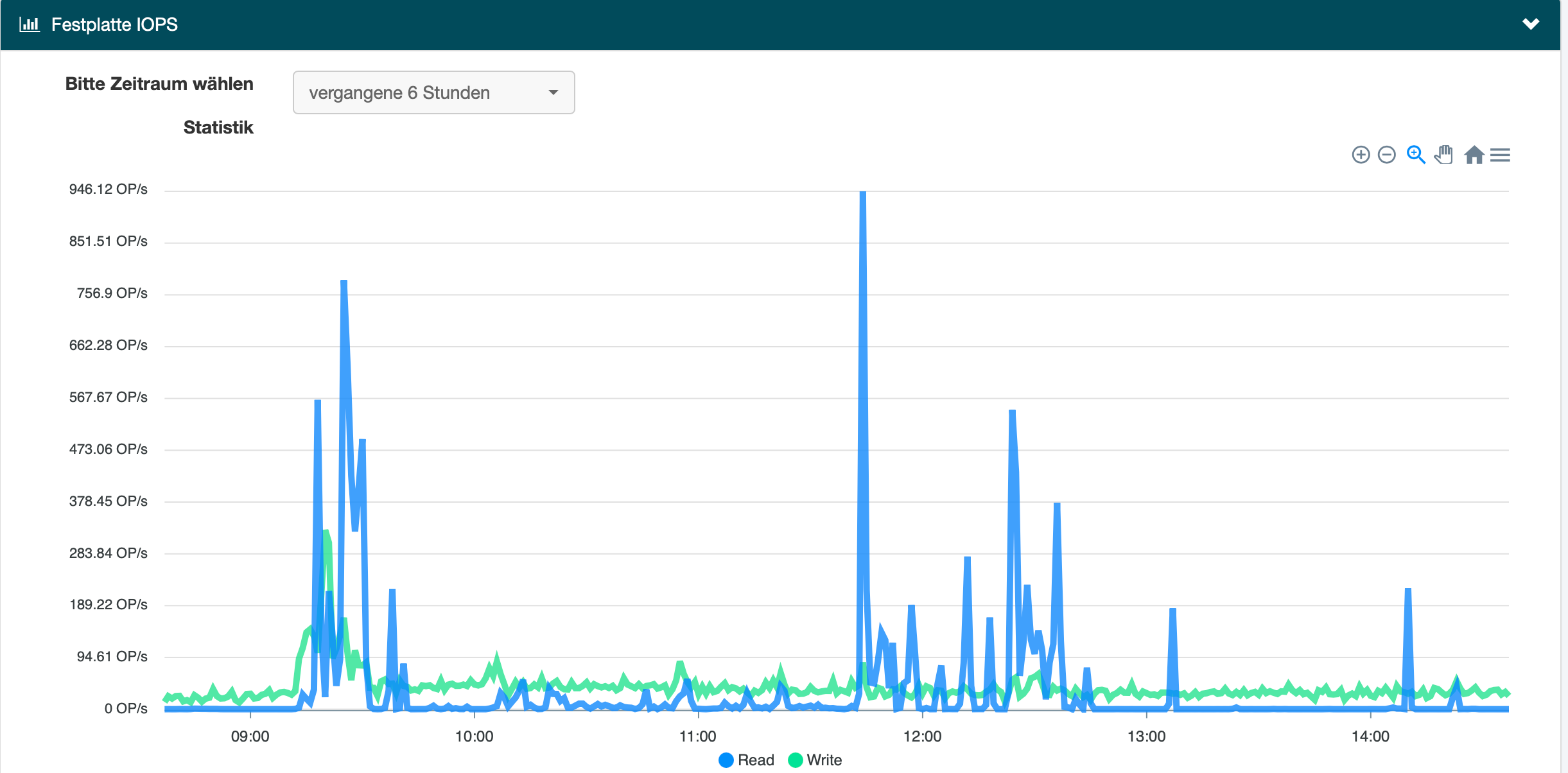
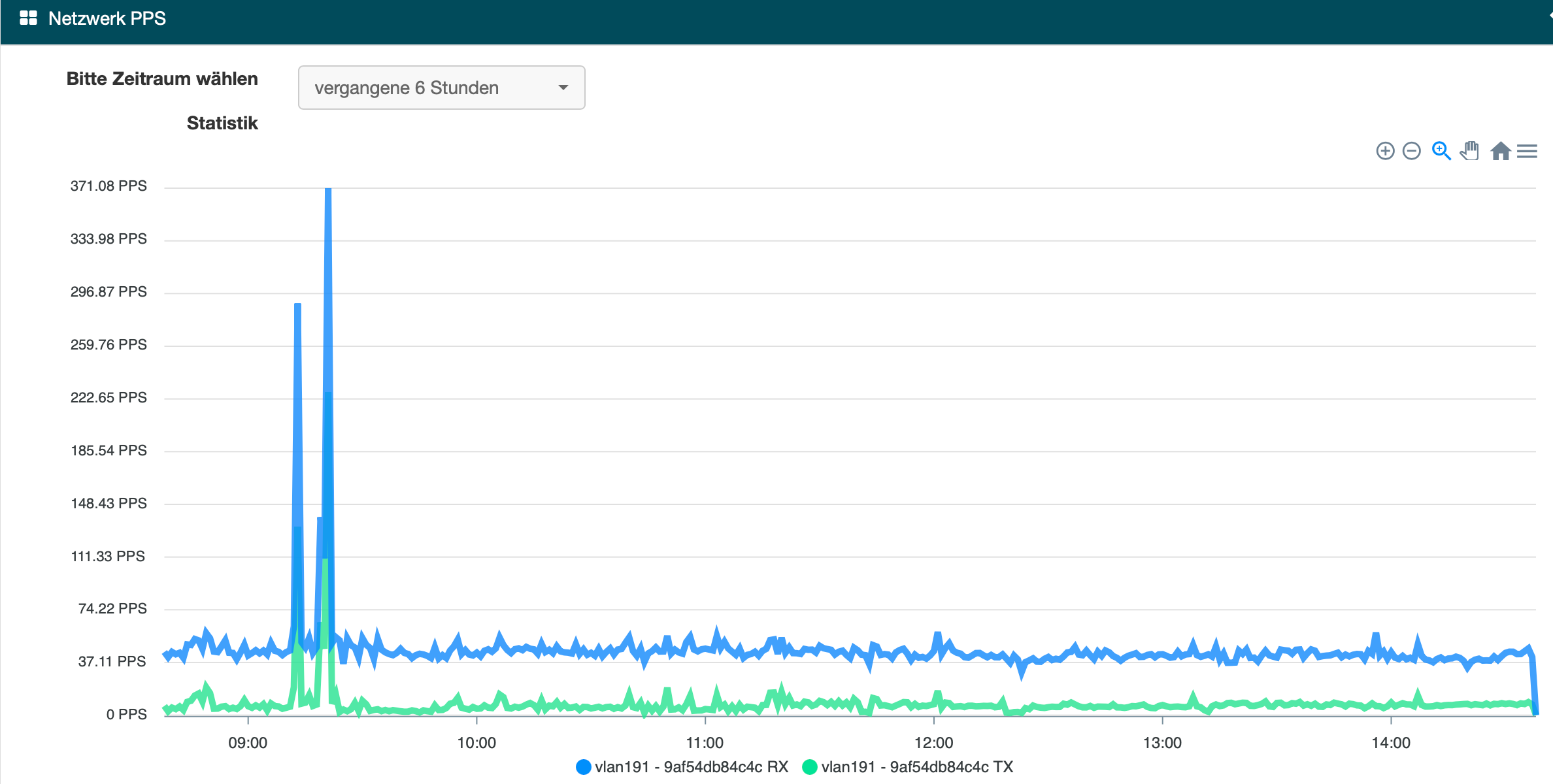
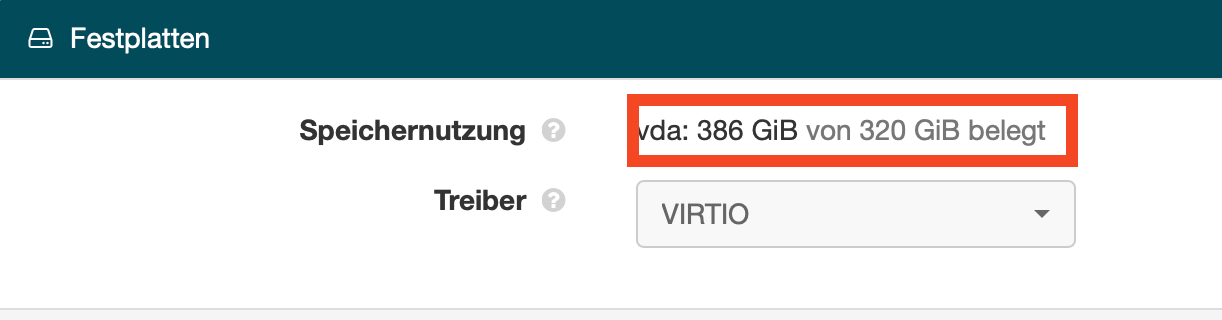
I suspect your disk has some issue… The CPU is blocked on I/O wait state!
The current value is 0.0%.
Top
top - 12:54:03 up 30 min, 1 user, load average: 13,27, 14,34, 16,64
Tasks: 306 total, 1 running, 305 sleeping, 0 stopped, 0 zombie
%CPU(s): 0,6 us, 0,6 sy, 0,0 ni, 4,1 id, 94,7 wa, 0,0 hi, 0,1 si, 0,0 st
MiB Spch: 15992,2 total, 4730,2 free, 1410,7 used, 10183,8 buff/cache
MiB Swap: 0,0 total, 0,0 free, 0,0 used. 14581,5 avail Spch
PID USER PR NI VIRT RES SHR S %CPU %MEM ZEIT+ BEFEHL
6883 mail2 20 0 1564824 36528 26020 S 1,7 0,2 0:00.23 podman
1460 root 20 0 2873044 117872 86088 D 1,0 0,7 0:13.90 promtail
6769 collabo+ 20 0 1491092 38372 25436 S 1,0 0,2 0:01.37 podman
927 api-ser+ 20 0 40304 13700 5552 S 0,7 0,1 0:04.70 redis-server
1913 traefik2 20 0 1386192 112228 80896 S 0,7 0,7 0:01.00 traefik
3596 503216 20 0 1362268 116352 47368 S 0,7 0,7 0:07.24 loki
6674 root 20 0 13528 6236 4028 R 0,7 0,0 0:00.30 top
6841 mail2 20 0 1564376 32944 24424 S 0,7 0,2 0:00.17 podman
6904 mail2 20 0 1417020 35440 23140 S 0,7 0,2 0:00.08 podman
49 root 20 0 0 0 0 D 0,3 0,0 0:00.60 kworker/u12:5+flush-254:0
174 root 20 0 0 0 0 I 0,3 0,0 0:03.87 kworker/5:1-events
489 message+ 20 0 9992 5588 4312 S 0,3 0,0 0:06.59 dbus-daemon
507 root 20 0 17416 8148 6920 S 0,3 0,0 0:02.94 systemd-logind
1200 lamp2 20 0 1234464 6568 2268 S 0,3 0,0 0:00.31 agent
1958 root 20 0 0 0 0 D 0,3 0,0 0:00.38 kworker/u12:13+flush-254:0
1959 root 20 0 0 0 0 I 0,3 0,0 0:00.59 kworker/u12:14-events_unbound
2581 100998 20 0 30732 10784 4464 S 0,3 0,1 0:03.35 redis-server
6731 roundcu+ 20 0 1491092 35524 25092 S 0,3 0,2 0:00.25 podman
6797 nextclo+ 20 0 1490580 37520 25168 S 0,3 0,2 0:00.18 podman
6874 mail2 20 0 1491860 35720 23088 S 0,3 0,2 0:00.13 podman