Good morning,
today I saw such a message 
Disks are dying? Is the problem with RAID?
A today, a little later I can do S.M.A.R.T.
Do you have any suggestions?
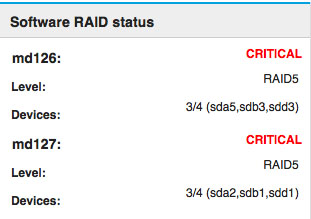
Thanks,
p.
Good morning,
today I saw such a message
Disks are dying? Is the problem with RAID?
A today, a little later I can do S.M.A.R.T.
Do you have any suggestions?
Thanks,
p.
It looks like sdc has dropped offline. See if it’s still alive; if not, you’ll need to replace it post haste.
The partition looks alive.
How can I restore it?
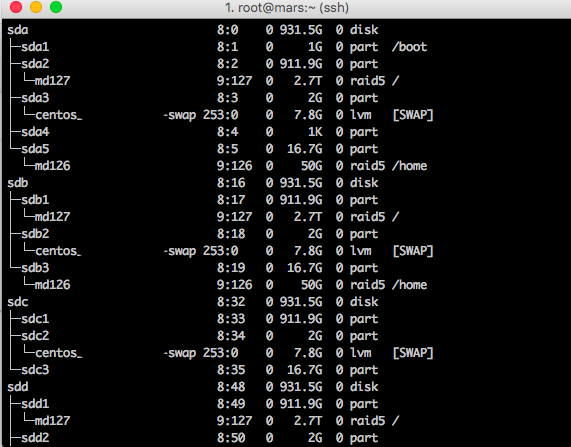
I would first try to investigate the failed HDD. Check in what kind of state the disk is. If there are badblocks, immediately change the disk for a new one.
If there are no bad blocks, you can try to re-add the disk to the raid array and let the array rebuild.
A quick search gave me this link: https://serverfault.com/questions/821966/how-to-re-add-a-drive-when-raid-is-in-degraded-mode
Replacing a failed disk in a raid5 array gave me this link: http://www.tjansson.dk/2013/12/replacing-a-failed-disk-in-a-mdadm-raid/
Please do check multiple information sources before you do anything. I would not rely on a single source anyway if I am not completely sure about the procedure…
Here is another good HowTo, it’s in german, but you’re from poland, so maybe you can understand it:
https://www.thomas-krenn.com/de/wiki/Mdadm_recovery_und_resync
https://www.thomas-krenn.com/de/wiki/Mdadm_recover_degraded_Array
I used sofwareraid before and had the same problem sometimes. With this I was able to recover the raid.
Now I use hardwareraid with sas-disks and had this problem never again. So maybe it would be worth to think about a hw-raid.
I am fixing a lot of softRAID
but cant halp without informations
We need your configuration file and the results of cat /proc/mdstat
but without this info, i will say sdac is gone. can be down or damage.
for that you are rigth smartcrtl is helpfull
Thank you! My results…
[root@mars ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md126 : active raid5 sda5[0] sdb3[1] sdd3[4]
52472832 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/3] [UU_U]
bitmap: 1/1 pages [4KB], 65536KB chunk
md127 : active raid5 sda2[0] sdb1[1] sdd1[4]
2868062208 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/3] [UU_U]
bitmap: 5/8 pages [20KB], 65536KB chunk
unused devices: <none>
[root@mars ~]# smartctl -a /dev/sdc
smartctl 6.5 2016-05-07 r4318 [x86_64-linux-3.10.0-957.10.1.el7.x86_64] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Red
Device Model: WDC WD10EFRX-68PJCN0
Serial Number: WD-WCC4J2339916
LU WWN Device Id: 5 0014ee 2b4706934
Firmware Version: 01.01A01
User Capacity: 1,000,204,886,016 bytes [1.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5400 rpm
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-2 (minor revision not indicated)
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Apr 30 11:04:00 2019 CEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 118) The previous self-test completed having
the read element of the test failed.
Total time to complete Offline
data collection: (13920) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 158) minutes.
Conveyance self-test routine
recommended polling time: ( 5) minutes.
SCT capabilities: (0x303d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 200 200 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 144 126 021 Pre-fail Always - 3758
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 383
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0
9 Power_On_Hours 0x0032 061 061 000 Old_age Always - 28725
10 Spin_Retry_Count 0x0032 100 100 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 100 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 373
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 258
193 Load_Cycle_Count 0x0032 185 185 000 Old_age Always - 45128
194 Temperature_Celsius 0x0022 114 104 000 Old_age Always - 29
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 58
200 Multi_Zone_Error_Rate 0x0008 100 253 000 Old_age Offline - 0
[root@mars ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 931.5G 0 disk
├─sda1 8:1 0 1G 0 part /boot
├─sda2 8:2 0 911.9G 0 part
│ └─md127 9:127 0 2.7T 0 raid5 /
├─sda3 8:3 0 2G 0 part
│ └─centos_spopalenica-swap 253:0 0 7.8G 0 lvm [SWAP]
├─sda4 8:4 0 1K 0 part
└─sda5 8:5 0 16.7G 0 part
└─md126 9:126 0 50G 0 raid5 /home
sdb 8:16 0 931.5G 0 disk
├─sdb1 8:17 0 911.9G 0 part
│ └─md127 9:127 0 2.7T 0 raid5 /
├─sdb2 8:18 0 2G 0 part
│ └─centos_spopalenica-swap 253:0 0 7.8G 0 lvm [SWAP]
└─sdb3 8:19 0 16.7G 0 part
└─md126 9:126 0 50G 0 raid5 /home
sdc 8:32 0 931.5G 0 disk
├─sdc1 8:33 0 911.9G 0 part
├─sdc2 8:34 0 2G 0 part
│ └─centos_spopalenica-swap 253:0 0 7.8G 0 lvm [SWAP]
└─sdc3 8:35 0 16.7G 0 part
sdd 8:48 0 931.5G 0 disk
├─sdd1 8:49 0 911.9G 0 part
│ └─md127 9:127 0 2.7T 0 raid5 /
├─sdd2 8:50 0 2G 0 part
│ └─centos_spopalenica-swap 253:0 0 7.8G 0 lvm [SWAP]
└─sdd3 8:51 0 16.7G 0 part
└─md126 9:126 0 50G 0 raid5 /home
sr0 11:0 1 1024M 0 romhello
thats more information 
Yor drive is not in the best condition but okay. befor you try to rapair the Raids. Please take a look on the connectirs for power. I had the same error. the y-cabel for power had no good connect.
you can read the Partions for sdc again.
the mdadm tool can handel your raids
do you build a conf file ? /etc/mdadm.conf
if not than buil it when your raids are rebuilded with
mdadm –detail –scan > /etc/mdadm.conf
but only when the raids are rebuilded
try this as your next step
mdadm –detail –scan
and by mdx too
mdadm –detail –scan /devb/md(x)
This is a sign the disk is starting to accumulate bad sectors. In time you will have to replace the disk. I would be rather safe than sorry and replace now.
O i am sorry robb is rigth
to fix it (with UEFI Server)
first save the partitiontabel of /dev/sda in a file
when you had datas out off the RAIDs on this disk backup them
then replace the disk
restart them
use gdisk and the file with the partitiontabel
than you can readd the partions to your raids
with gdisk you can saver the partitiont
Checking the connection, but hdd to exchange.
Thank you guys for help!