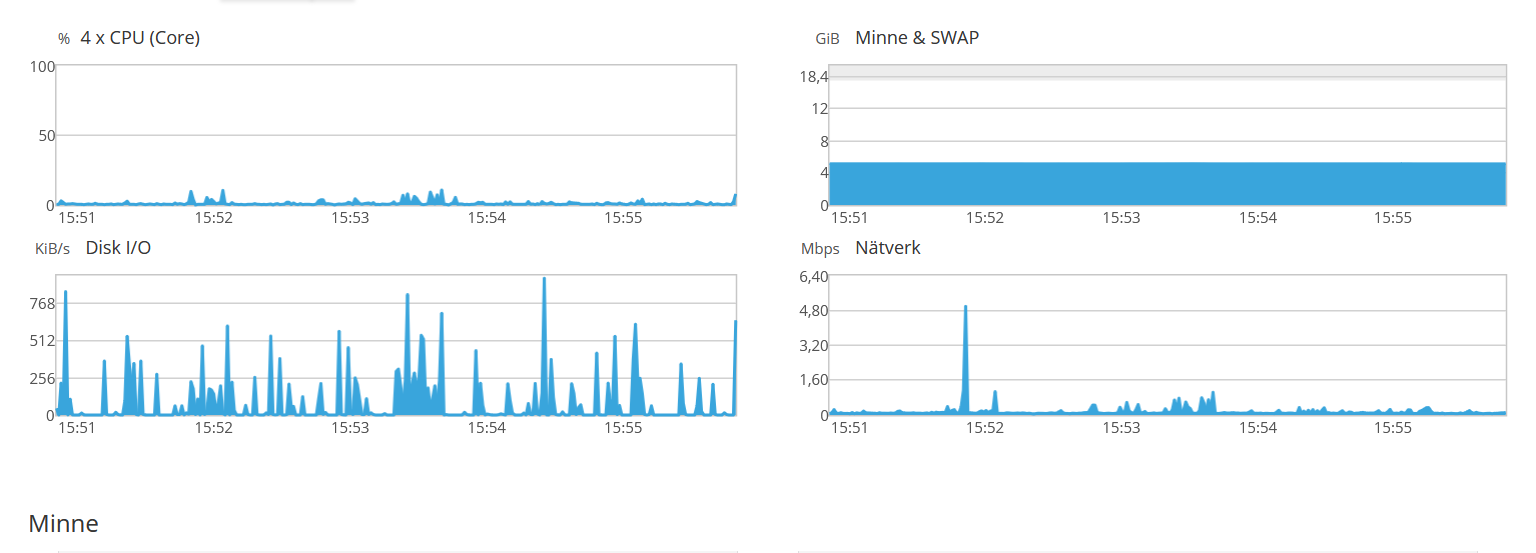
Recently we have a strange behavior, I hope somebody could find the solution. Th…ank you for your help in advance.
We using sssd plugged to LDAP on our ssh server.
Server is installed on
> Distributor ID: Debian
> Description: Debian GNU/Linux 11 (bullseye)
> Release: 11
> Codename: bullseye
Here are the version of sssd packages :
```
ii sssd 2.4.1-2
ii sssd-ad 2.4.1-2
ii sssd-ad-common 2.4.1-2
ii sssd-common 2.4.1-2
ii sssd-dbus 2.4.1-2
ii sssd-ipa 2.4.1-2
ii sssd-krb5 2.4.1-2
ii sssd-krb5-common 2.4.1-2
ii sssd-ldap 2.4.1-2
ii sssd-proxy 2.4.1-2
ii sssd-tools 2.4.1-2
```
Here is **sssd.conf** :
```
[sssd]
#services = nss, pam
config_file_version = 2
domains = domain
timeout = 15
[nss]
# Ensure that certain users are not authenticated from network accounts
filter_users = root,lightdm,nslcd,dnsmasq,dbus,avahi,avahi-autoipd,backup,beagleindex,bin,daemon,games,gdm,gnats,haldaemon,hplip,irc,ivman,klog,libuuid,list,lp,mail,man,messagebus,mysql,news,ntp,openldap,polkituser,proxy,pulse,puppet,saned,sshd,sync,sys,syslog,uucp,vde2-net,www-data
filter_groups = root
[domain/domain]
debug_level = 5
id_provider = ldap
access_provider = ldap
auth_provider = ldap
autofs_provider = ldap
ldap_schema = rfc2307
ldap_uri = ldaps://ldap.domain/ , ldaps://ldap-master.domain/
ldap_search_base = o=domain,dc=xxx,dc=xx
ldap_id_use_start_tls = True
cache_credentials = False
ldap_group_member = memberUid
ldap_access_filter = (objectClass=posixAccount)
ldap_tls_cacertdir = /etc/ssl/certs
#ldap_tls_cacert = /etc/ssl/certs/mytlsca.pem # Replace with the correct file name
ldap_tls_reqcert = allow
# Enables listing users and groups with getent
enumerate = True
```
Globally it works perfectly, but sometimes sssd process is killed by watchdog and then it can't start up again.
1) The reason for sssd to be killed by watchdog is probably explained by server's load.
This load by itself is also strange thing, but probably not linked with sssd.
**sssd.log** (with debug_level=5)
```
(2022-06-14 0:31:43): [sssd] [svc_child_info] (0x0020): Child [24079] ('domain':'%BE_domain') was terminated by own WATCHDOG
(2022-06-14 0:32:25): [sssd] [svc_child_info] (0x0020): Child [88706] ('domain':'%BE_domain') was terminated by own WATCHDOG
```
2) Then the sssd service tried to restart, but failed partially
I see these lines in sssd_pam and sssd_nss logs :
**sssd_pam.log**
```
(2022-06-14 0:31:31): [pam] [server_setup] (0x0040): Starting with debug level = 0x0070
(2022-06-14 0:31:43): [pam] [sbus_dbus_connect_address] (0x0020): Unable to register to unix:path=/var/lib/sss/pipes/private/sbus-dp_domain [org.freedesktop.DBus.Error.NoReply]: Did not receive a reply. Possible causes include: the remote application did not send a reply, the message bus security policy blocked the reply, the reply timeout expired, or the network connection was broken.
(2022-06-14 0:31:43): [pam] [sss_dp_init] (0x0010): Failed to connect to backend server.
(2022-06-14 0:31:43): [pam] [sss_process_init] (0x0010): fatal error setting up backend connector
(2022-06-14 0:31:43): [pam] [pam_process_init] (0x0010): sss_process_init() failed
(2022-06-14 0:31:43): [pam] [server_setup] (0x0040): Starting with debug level = 0x0070
(2022-06-14 0:31:43): [pam] [sbus_dbus_connect_address] (0x0020): Unable to connect to unix:path=/var/lib/sss/pipes/private/sbus-dp_domain [org.freedesktop.DBus.Error.NoServer]: Failed to connect to socket /var/lib/sss/pipes/private/sbus-dp_domain: Connection refused
(2022-06-14 0:31:43): [pam] [sss_dp_init] (0x0010): Failed to connect to backend server.
(2022-06-14 0:31:43): [pam] [sss_process_init] (0x0010): fatal error setting up backend connector
(2022-06-14 0:31:43): [pam] [pam_process_init] (0x0010): sss_process_init() failed
```
**sssd_nss.log**
```
(2022-06-14 0:31:44): [nss] [sbus_dbus_connect_address] (0x0020): Unable to connect to unix:path=/var/lib/sss/pipes/private/sbus-dp_domain [org.freedesktop.DBus.Error.NoServer]: Failed to connect to socket /var/lib/sss/pipes/private/sbus-dp_domain: Connection refused
(2022-06-14 0:31:44): [nss] [sbus_reconnect_attempt] (0x0020): Unable to connect to D-Bus
(2022-06-14 0:31:47): [nss] [sbus_dbus_connect_address] (0x0020): Unable to connect to unix:path=/var/lib/sss/pipes/private/sbus-dp_domain [org.freedesktop.DBus.Error.NoServer]: Failed to connect to socket /var/lib/sss/pipes/private/sbus-dp_domain: Connection refused
(2022-06-14 0:31:47): [nss] [sbus_reconnect_attempt] (0x0020): Unable to connect to D-Bus
(2022-06-14 0:32:12): [nss] [server_setup] (0x0040): Starting with debug level = 0x0070
(2022-06-14 0:32:25): [nss] [sbus_dbus_connect_address] (0x0020): Unable to register to unix:path=/var/lib/sss/pipes/private/sbus-dp_domain [org.freedesktop.DBus.Error.NoReply]: Did not receive a reply. Possible causes include: the remote application did not send a reply, the message bus security policy blocked the reply, the reply timeout expired, or the network connection was broken.
(2022-06-14 0:32:25): [nss] [sss_dp_init] (0x0010): Failed to connect to backend server.
(2022-06-14 0:32:25): [nss] [sss_process_init] (0x0010): fatal error setting up backend connector
(2022-06-14 0:32:25): [nss] [nss_process_init] (0x0010): sss_process_init() failed
```
I said "partially" as sssd. service has active status by itself, but it doesn't work properly and no authentication is possible.
**sssd_pam.log**
```
(2022-06-14 8:31:06): [pam] [cache_req_common_process_dp_reply] (0x0040): CR #1: Could not get account info [1432158311]: Unknown service
(2022-06-14 8:31:56): [pam] [cache_req_common_process_dp_reply] (0x0040): CR #3: Could not get account info [1432158311]: Unknown service
```
3) The reason why sssd doesn't work is probably caused by services sssd-pam and sssd-nss that failed to restart.
> journalctl -u sssd-nss.service
```
Jun 14 00:32:11 ssh systemd[1]: sssd-nss.service: Main process exited, code=exited, status=70/SOFTWARE
Jun 14 00:32:11 ssh systemd[1]: sssd-nss.service: Failed with result 'exit-code'.
Jun 14 00:32:11 ssh systemd[1]: sssd-nss.service: Scheduled restart job, restart counter is at 1.
Jun 14 00:32:11 ssh systemd[1]: Stopped SSSD NSS Service responder.
Jun 14 00:32:11 ssh systemd[1]: Started SSSD NSS Service responder.
Jun 14 00:32:12 ssh sssd_nss[88732]: Starting up
Jun 14 00:32:25 ssh systemd[1]: sssd-nss.service: Main process exited, code=exited, status=3/NOTIMPLEMENTED
Jun 14 00:32:25 ssh systemd[1]: sssd-nss.service: Failed with result 'exit-code'.
Jun 14 00:32:26 ssh systemd[1]: sssd-nss.service: Scheduled restart job, restart counter is at 2.
Jun 14 00:32:26 ssh systemd[1]: Stopped SSSD NSS Service responder.
Jun 14 00:32:26 ssh systemd[1]: Started SSSD NSS Service responder.
Jun 14 00:32:26 ssh sssd_nss[88739]: Starting up
Jun 14 00:35:07 ssh systemd[1]: sssd-nss.service: Main process exited, code=exited, status=70/SOFTWARE
Jun 14 00:35:07 ssh systemd[1]: sssd-nss.service: Failed with result 'exit-code'.
Jun 14 00:35:07 ssh systemd[1]: sssd-nss.service: Scheduled restart job, restart counter is at 3.
Jun 14 00:35:07 ssh systemd[1]: Stopped SSSD NSS Service responder.
Jun 14 00:35:07 ssh systemd[1]: Started SSSD NSS Service responder.
Jun 14 00:35:07 ssh sssd_nss[88795]: Starting up
[skip]
Jun 14 00:36:20 ssh systemd[1]: Started SSSD NSS Service responder.
Jun 14 00:36:21 ssh systemd[1]: sssd-nss.service: Main process exited, code=exited, status=3/NOTIMPLEMENTED
Jun 14 00:36:21 ssh systemd[1]: sssd-nss.service: Failed with result 'exit-code'.
Jun 14 00:36:21 ssh systemd[1]: sssd-nss.service: Scheduled restart job, restart counter is at 12.
Jun 14 00:36:21 ssh systemd[1]: Stopped SSSD NSS Service responder.
Jun 14 00:36:21 ssh systemd[1]: sssd-nss.service: Start request repeated too quickly.
Jun 14 00:36:21 ssh systemd[1]: sssd-nss.service: Failed with result 'exit-code'.
Jun 14 00:36:21 ssh systemd[1]: Failed to start SSSD NSS Service responder.
```
> journalctl -u sssd-nss.socket
```
Jun 14 00:36:21 ssh systemd[1]: sssd-nss.socket: Failed with result 'service-start-limit-hit'.
```
> journalctl -u sssd-pam.service
```
Jun 14 00:30:50 ssh sssd_pam[88640]: Starting up
Jun 14 00:31:31 ssh systemd[1]: sssd-pam.service: Main process exited, code=exited, status=70/SOFTWARE
Jun 14 00:31:31 ssh systemd[1]: sssd-pam.service: Failed with result 'exit-code'.
Jun 14 00:31:31 ssh systemd[1]: sssd-pam.service: Scheduled restart job, restart counter is at 1.
Jun 14 00:31:31 ssh systemd[1]: Stopped SSSD PAM Service responder.
Jun 14 00:31:31 ssh systemd[1]: Starting SSSD PAM Service responder...
Jun 14 00:31:31 ssh systemd[1]: Started SSSD PAM Service responder.
Jun 14 00:31:43 ssh systemd[1]: sssd-pam.service: Main process exited, code=exited, status=3/NOTIMPLEMENTED
Jun 14 00:31:43 ssh systemd[1]: sssd-pam.service: Failed with result 'exit-code'.
Jun 14 00:31:43 ssh systemd[1]: sssd-pam.service: Scheduled restart job, restart counter is at 2.
Jun 14 00:31:43 ssh systemd[1]: Stopped SSSD PAM Service responder.
Jun 14 00:31:43 ssh systemd[1]: Starting SSSD PAM Service responder...
Jun 14 00:31:43 ssh systemd[1]: Started SSSD PAM Service responder.
Jun 14 00:31:43 ssh systemd[1]: sssd-pam.service: Main process exited, code=exited, status=3/NOTIMPLEMENTED
Jun 14 00:31:43 ssh systemd[1]: sssd-pam.service: Failed with result 'exit-code'.
Jun 14 00:31:43 ssh systemd[1]: sssd-pam.service: Scheduled restart job, restart counter is at 3.
Jun 14 00:31:43 ssh systemd[1]: Stopped SSSD PAM Service responder.
[skip]
Jun 14 00:36:20 ssh systemd[1]: sssd-pam.service: Start request repeated too quickly.
Jun 14 00:36:20 ssh systemd[1]: sssd-pam.service: Failed with result 'exit-code'.
Jun 14 00:36:20 ssh systemd[1]: Failed to start SSSD PAM Service responder.
```
> journalctl -u sssd-pam.socket
```
Jun 14 00:31:44 ssh systemd[1]: sssd-pam.socket: Failed with result 'service-start-limit-hit'.
Jun 14 00:32:11 ssh systemd[1]: Starting SSSD PAM Service responder socket.
Jun 14 00:32:12 ssh systemd[1]: Listening on SSSD PAM Service responder socket.
Jun 14 00:36:20 ssh systemd[1]: sssd-pam.socket: Failed with result 'service-start-limit-hit'.
```
So, this is pretty serious as it happens often enough and ssh server become useless until we restart sssd service.
Restarting sssd service solves the problem, but I hope there is some better solution.
Here some additional details/thoughts :
- I used some old conf file as template for sssd conf for this server.
There was "service" setting in this conf in the sssd part :
[sssd]
services = nss, pam
As I understand this option is not necessary now. So I comment this line.
The problem described above was already present, and commenting this line didn't solve it.
But still I'd like to mention this change.
- I added
`timeout = 15` option into sssd part of config, but it didn't help neither.
- There is an option "RestartSec" for systemd.
I'm wondering may be set this option for sssd-nss and sssd-pam services could change something (may be the problem that sssd-nss restart too quickly) ?