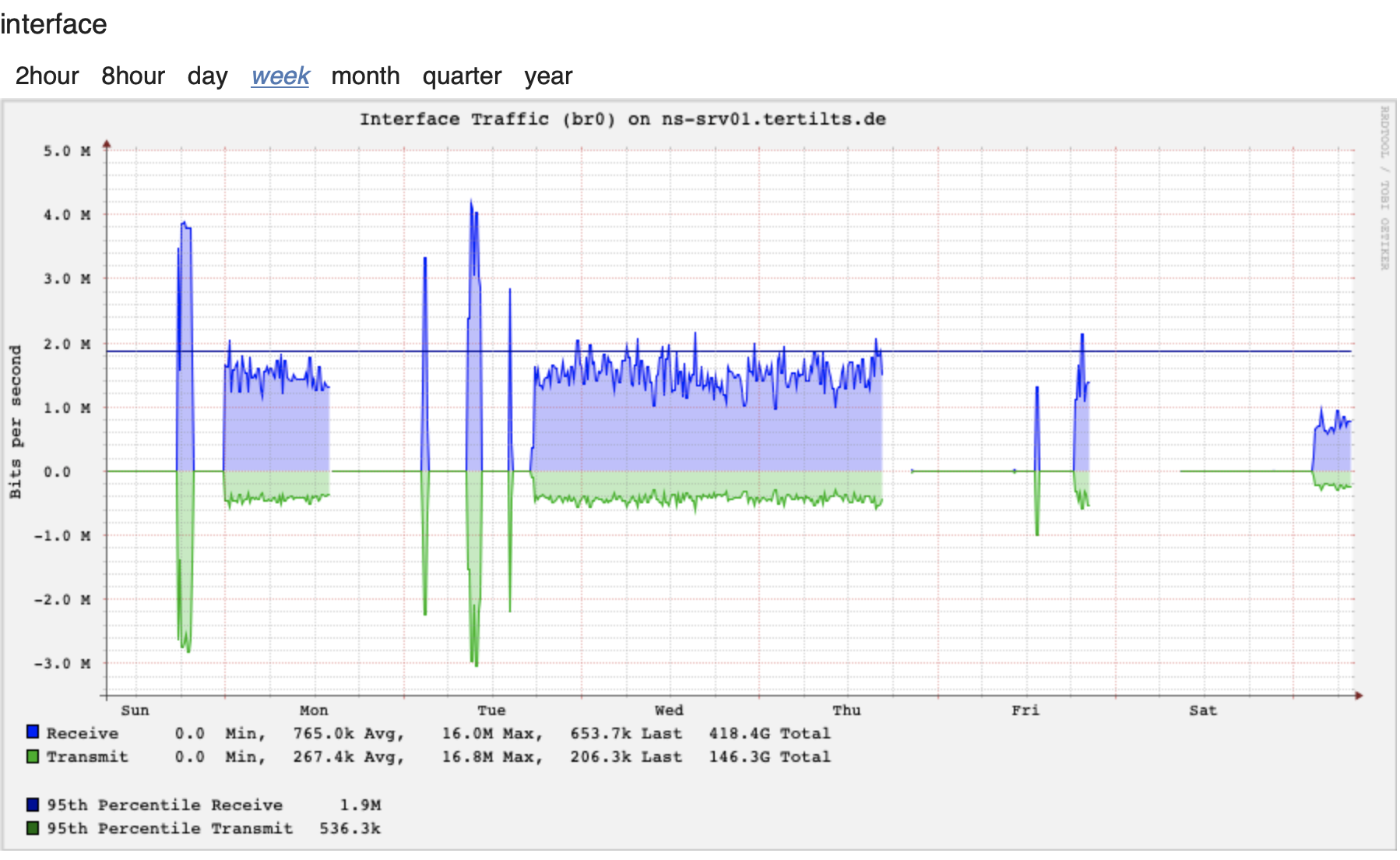
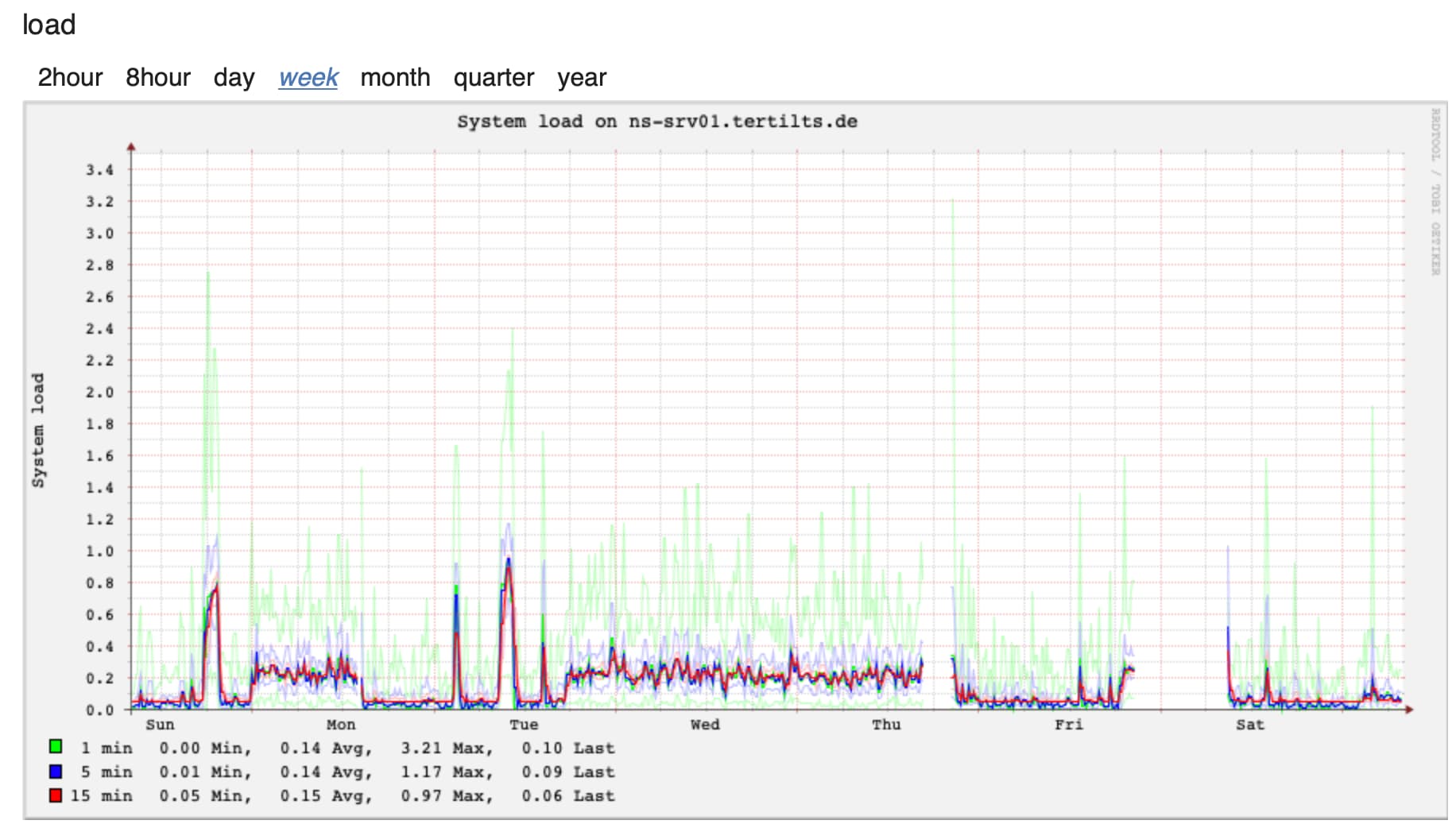
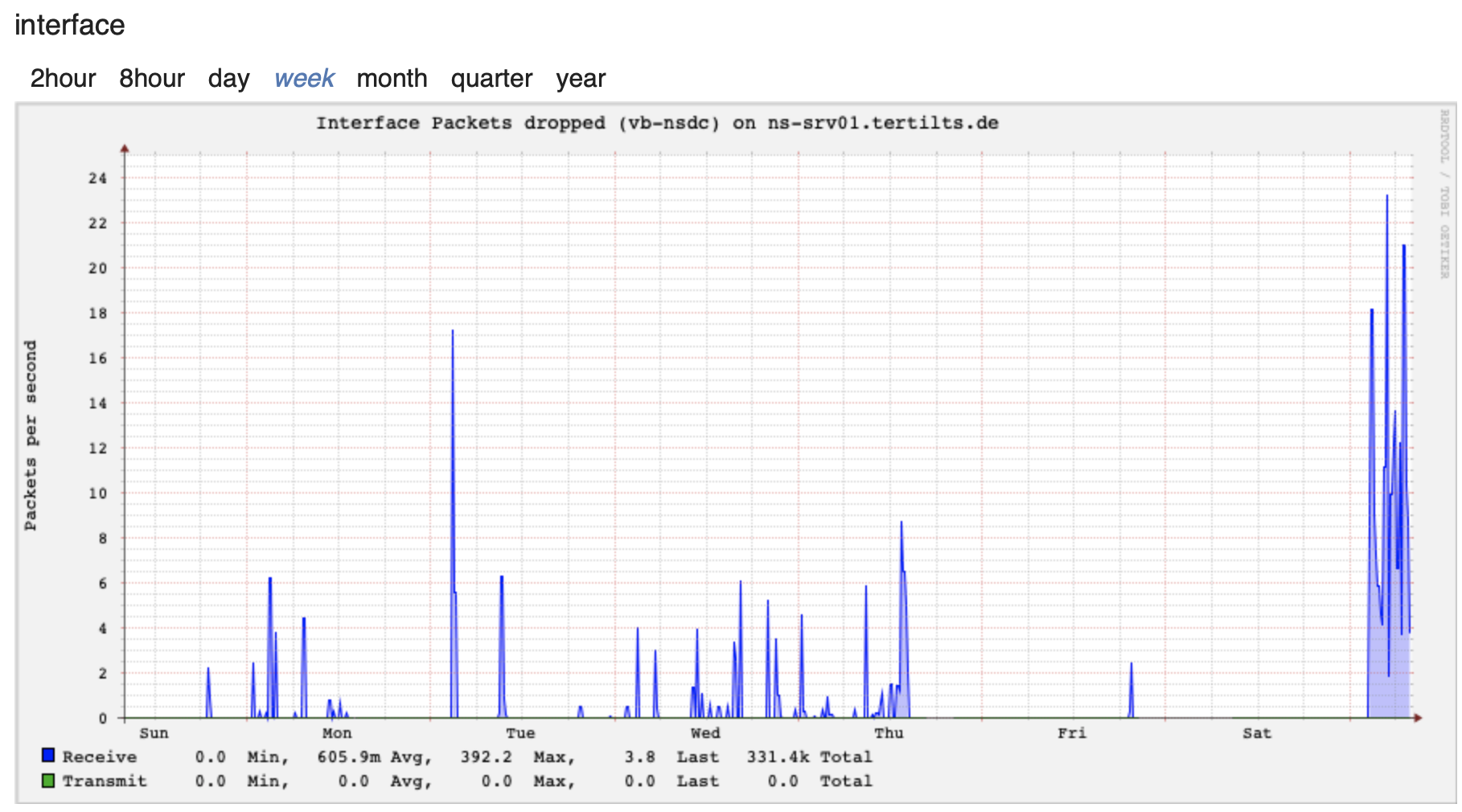
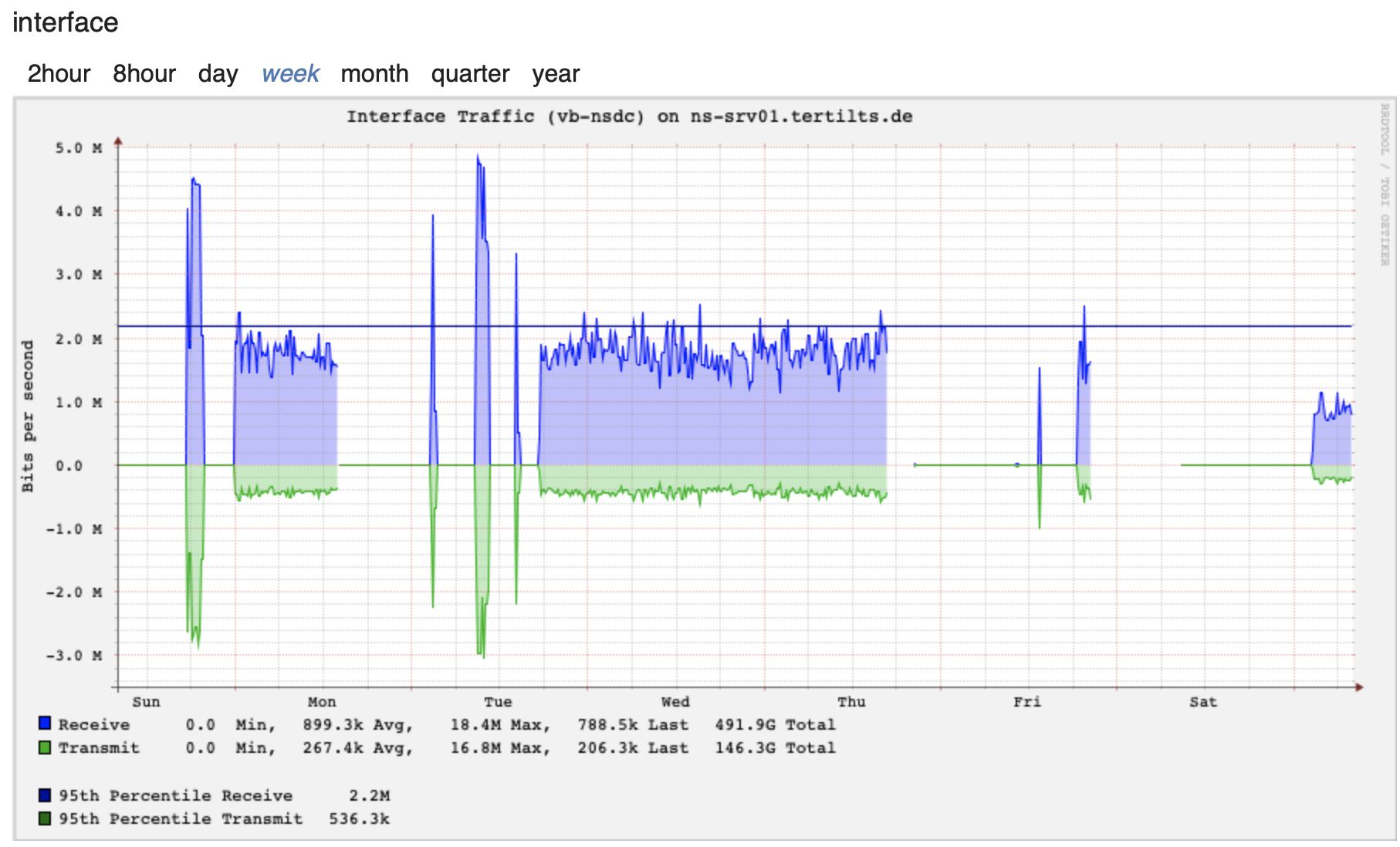
Hello,
my server freezes regularly and there are kernel messages on the console that look like a hardware problem to me.
[774471.637004] task: ffff8e23f4bd6300 ti: ffff8e2276f40000 task.ti: ffff8e2276f40000
[774471.637004] RIP: 001B: [<ffffffffc067177d>] [<ffffffffc067177d>] nf_ct_ deliver cached events+0x2d/Bx110 Inf _conntrack]
[774471.637004] RSP: 0018:ffff8e2276 43760 EFLAGS: 00010246
(774471.637004] RAX: 0000000000000000 RBX: fff8e222584b140 RCX:00000001800c00Ba
(774471.637004] RDX: ffff8e2276f43fd8 RSI: 0000000000000200 RDI: ffff8e222584b140
[774471.637004] RBP: ffff8e2276f437a0 RBB: ffff8e222584b140 R09:
000001800c00Ba
[774471.637004] R10: 000000002584ba01 R11: ffff8e222584b140 R12: ffff8e222584b140
[774471.637004] R13: ffff8e221417a800 R14: ffffffffb7b682eB R15: 0000000000008000
[774471.637004] FS: 00007fe1c29 4700 (0000) GS: ffff8e23ffd00000 (0000) knlGS:0000000000000000
[774471.637004] CS: 0010 DS: 0000 ES: 0000 CRO:0000000080050033
[774471.637004] CR2: 000000000000030 CR3: 0000000235/7a000 CR4 : 0000000000340fe0
[774471.637004] Call Trace:
[774471.637004] [<ffffffffc06892ce>] ipv4_confirm+0x4e/Bx100[nf_conntrack_ipv41
[774471.637004] [<ffffffff67499ab8>]nf_iterate+0x98/BxeB
[774471.637004] [<ffffffffb7499ba8>]nf_hook_slow+@xa8/0x110
[774471.637004] [<ffffffffb74ab24a>] ip_output+Bxda/BxfB
[774471.637004] [<rfffffffb74aa5fB)) ?
ip_append_data.isra.50+0xa60/Bxa60
[774471.637004] [‹rfffffffb74a81c5›]dst_output_sk+8x15/8x20
[774471.637004] [<ffffffffb749aeba>]nf_reinject+0xca/0x1a0
[774471.637004] [<ffffffffc8623566>]nfqnl_recv_verdict+Bx216/Bx318[nfnetlink_queuel
[774471.637004] [<ffffffffb71b5386>]?nla_parse+@xb6/8x120
[774471.637004] [‹ffffffffb749b6aZ›]nfnetlink_rcv_msg+Bx162/Bx270
[774471.637004] [‹fffffffb6ed4abe)] ? finish task switch+0x4e/Bx1c0
[774471.637004] [<rfffffffb749b540>]?nfnetlink_net_exit_batch+0x78/Bx70
(774471.637804] [<ffffffffb749711b>]netlink_rcv_skb+Bxab/BxcB
[774471.637004] [<ffffffffb749bb8f>]nfnetlink_rcv+0x28f/8x588
[774471.637004] [<ffffffffb74953f3>]? _netlink_lookup+Bxd3/8x130
[774471.637004] [<ffffffffb7496aa@›]netlink_unicast+0x170/8x210
[774471.637004] [‹ffffffffb719d6eZ>]?memcpy_fromiovec+@x62/BxbB
[774471.637004] [<ffffffffb7496e48>]netlink_sendmsg+0x308/8x420
[774471.637004] [<ffffffffb74393a6>]sock_sendmsg+0xb6/BxfB
[774471.637004] [<ffffffffb6ed3233>] ? wake_wp+8x13/Bx28
[774471.637004] [<ffffffff674945f2>] ? netlink_recumsg+Bx212/9x490
[774471.637004] [<ffffffffb758cB6B>]?__schedule+0x320/8x680
[774471.637004] [‹rfffffffb743a269>]
_sys_sendmsg+Bx3e9/0x400
[774471.637004] [<ffffffffb74396a7)]? SYSC_recvfrom+Bx127/8x160
[774471.637004] [‹ffffffffb743b921>] _sys_sendmsg+0x51/8x98
[774471.637004] [<ffffffffb743b972>] SyS_sendmsg+Bx12/Bx28
[774471.637004] [<ffffffffb7599r92>] system_call_fastpath+0x25/BxZa
[774471.637004] Code: 66 66 90 55 48 89 e5
56 41 55 41 54 53 48 89 fb 48 83 ec 20 65 48 8b 04 25 28 00 00 00 48 89 45 d8 31 c
0 48 8b 87 f8 00 00 00 <48> 8b 98 30 Ba BO 80 48 85 d2 Br 84 83 00 00 00 48 8b 87 e8 00
(774471.637004] RIP [<Ffffffffc067177d>] nf_ct_deliver_cached_events+Bx2d/8x110 Inf_conntrack]
[774471.637004] RSP<ffff8e2276f43760>
[774471.637004] CR2: 0000000000000a30
[774471.637004] ---[ end trace Bee870e761695200 ]---
[774471.637004] Kernel panic
not syncing: Fatal exception in interrupt
(774471.637004] Kernel Offset: @x35e00000 from Oxffffffff8100000 (relocation range: Oxffffffff800000BB-Oxffffffffbfffffff)
I wrote to the provider support 2 days ago… no response.
Does anyone have any idea?
Best regards, Marko