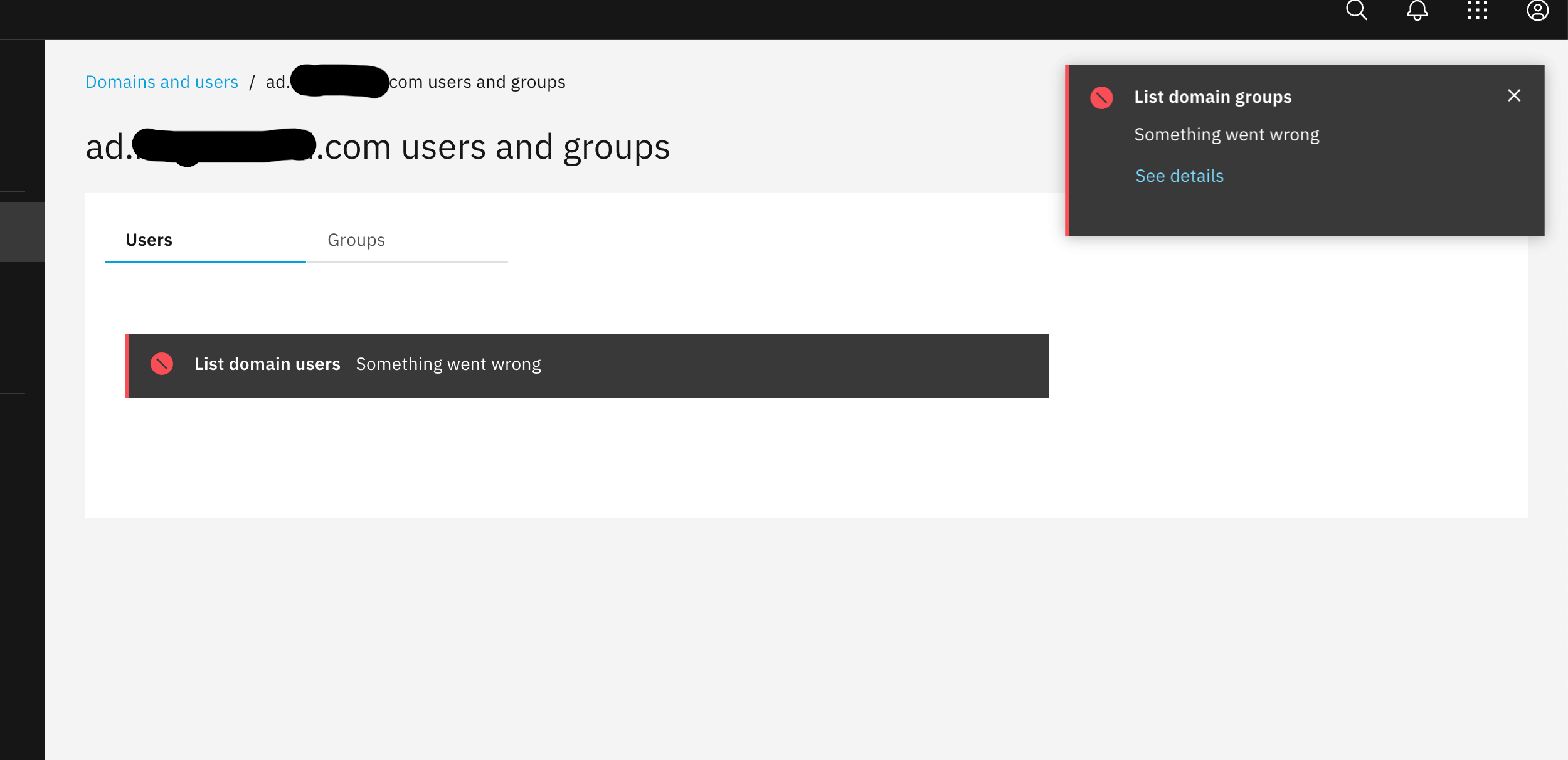
I am giving NS8B2 a try on my VPS host (Contabo). I have installed Rocky 9 and followed NS8 install documentation. I can enter the closer admin guy and configure the node and install LDAP (local node1), but is throws me an error:
Traceback (most recent call last):
File “/var/lib/nethserver/cluster/actions/list-domain-users/50list_users”, line 33, in
users = Ldapclient.factory(**domain).list_users()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/agent/pypkg/agent/ldapclient/init.py”, line 29, in factory
return LdapclientAd(**kwargs)
^^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/agent/pypkg/agent/ldapclient/base.py”, line 37, in init
self.ldapconn = ldap3.Connection(self.ldapsrv,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File “/usr/local/agent/pyenv/lib64/python3.11/site-packages/ldap3/core/connection.py”, line 363, in init
self._do_auto_bind()
File “/usr/local/agent/pyenv/lib64/python3.11/site-packages/ldap3/core/connection.py”, line 387, in _do_auto_bind
self.open(read_server_info=False)
File “/usr/local/agent/pyenv/lib64/python3.11/site-packages/ldap3/strategy/sync.py”, line 57, in open
BaseStrategy.open(self, reset_usage, read_server_info)
File “/usr/local/agent/pyenv/lib64/python3.11/site-packages/ldap3/strategy/base.py”, line 146, in open
raise exception_history[0][0]
ldap3.core.exceptions.LDAPSocketOpenError: socket connection error while opening: [Errno 111] Connection refused
Sounds/seesfamiliar anybody please? I’ve also deleted the LDAP instance and re-tryed with Samba, same issue.
the ldap module is unresponsive probably or not well installed, the list user action throw an exception about connection refused…what ldap did you choose, samba4, openldap ?
what are the resources you allocated to the VM Ram, cpu
nothing curious, maybe some curious networking could do it, we need the log of installation and usage of each module eg openldap1 or samba1. (installation and usage)
I have reproduced your installation on my Proxmox. BaseOS Rocky 9.2, 4 CPU cores, 8 GB RAM and 100 GB disk. I proceeded exactly as you described. Users and groups can be created without problems.
For everyone else, to get a dump of recent records:
journalctl > journal.txt
The same information can be obtained from the Logs page, filtering for a specific node.
About the issue, I suspect it is a bug in the Ldapproxy, which tries to bind a missing IPv6 loopback address. The failure of both Samba and OpenLDAP user listings is just a symptom of that.
This is the log evidence:
Oct 02 23:08:29 srv1 ldapproxy[20659]: 2023/10/02 21:08:29 [emerg] 1#1: bind() to [::1]:20001 failed (99: Address not available)
@LayLow can you confirm that the Contabo VPS has no IPv6?