NethServer Version: 7.9.2009
Module: NS8 migration
Hi @davidep
This is second attempt to migrate a current NethServer 7.9 to a new NS8.
The first attempt was done a week ago, but not finished.
The target NS8 is a fresh install to RC1.
However:
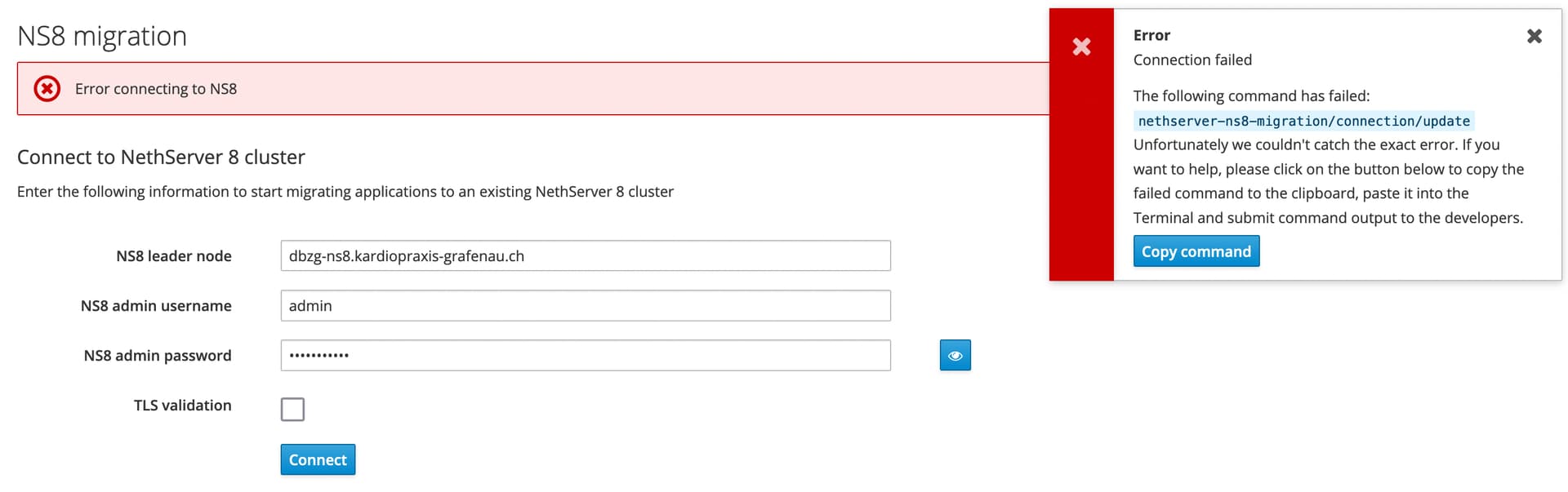
Any attempt to connect to NS8 Cluster fails.
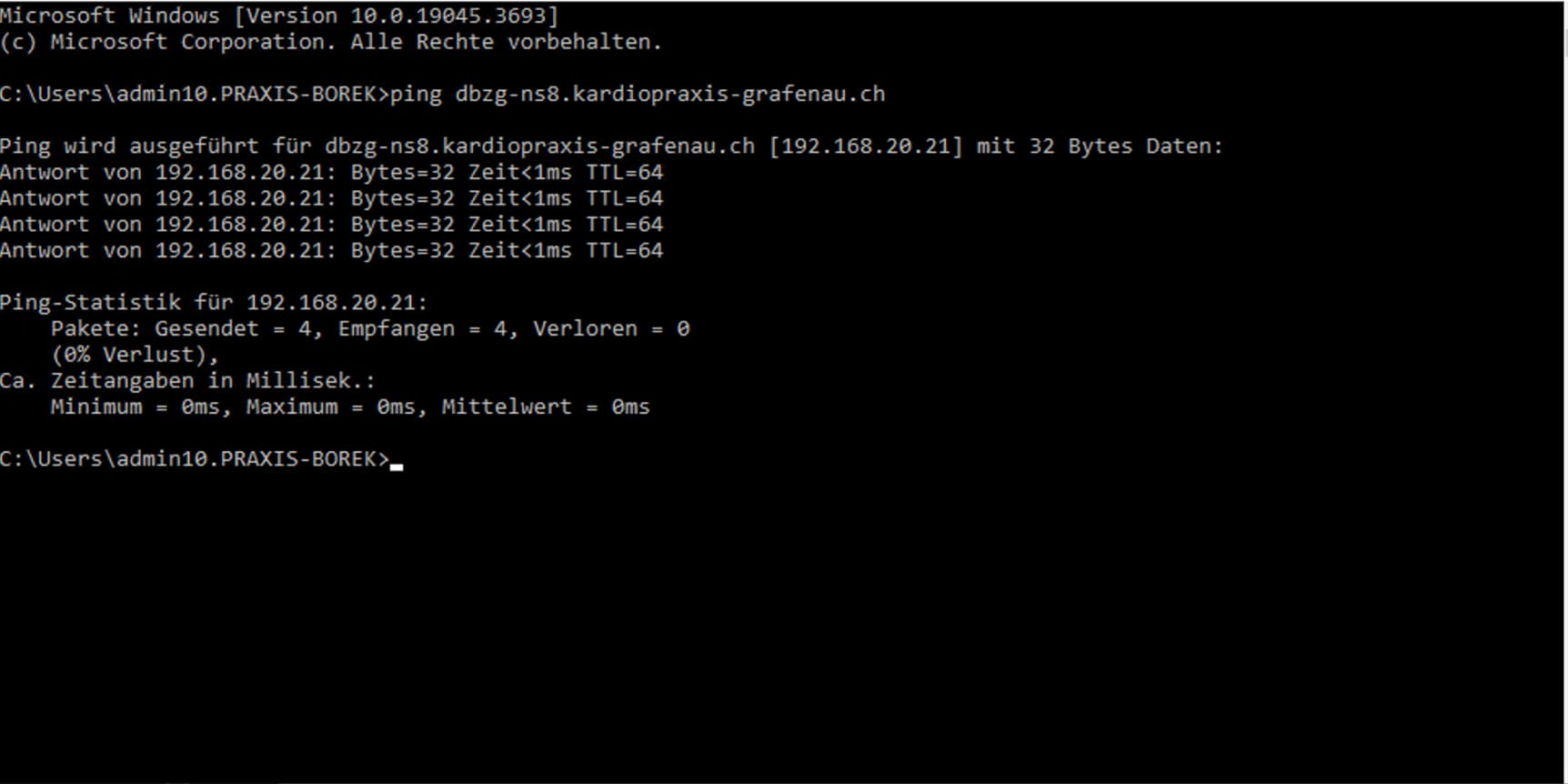
Internal DNS resolution is fully working.
A second attempt will produce an error message saying:

This is a leftover from the attempt at migration last week
The problem seems from a local flag set last week:
subprocess.run(['/sbin/e-smith/signal-event', '-j', 'nethserver-ns8-migration-save'], check=True)
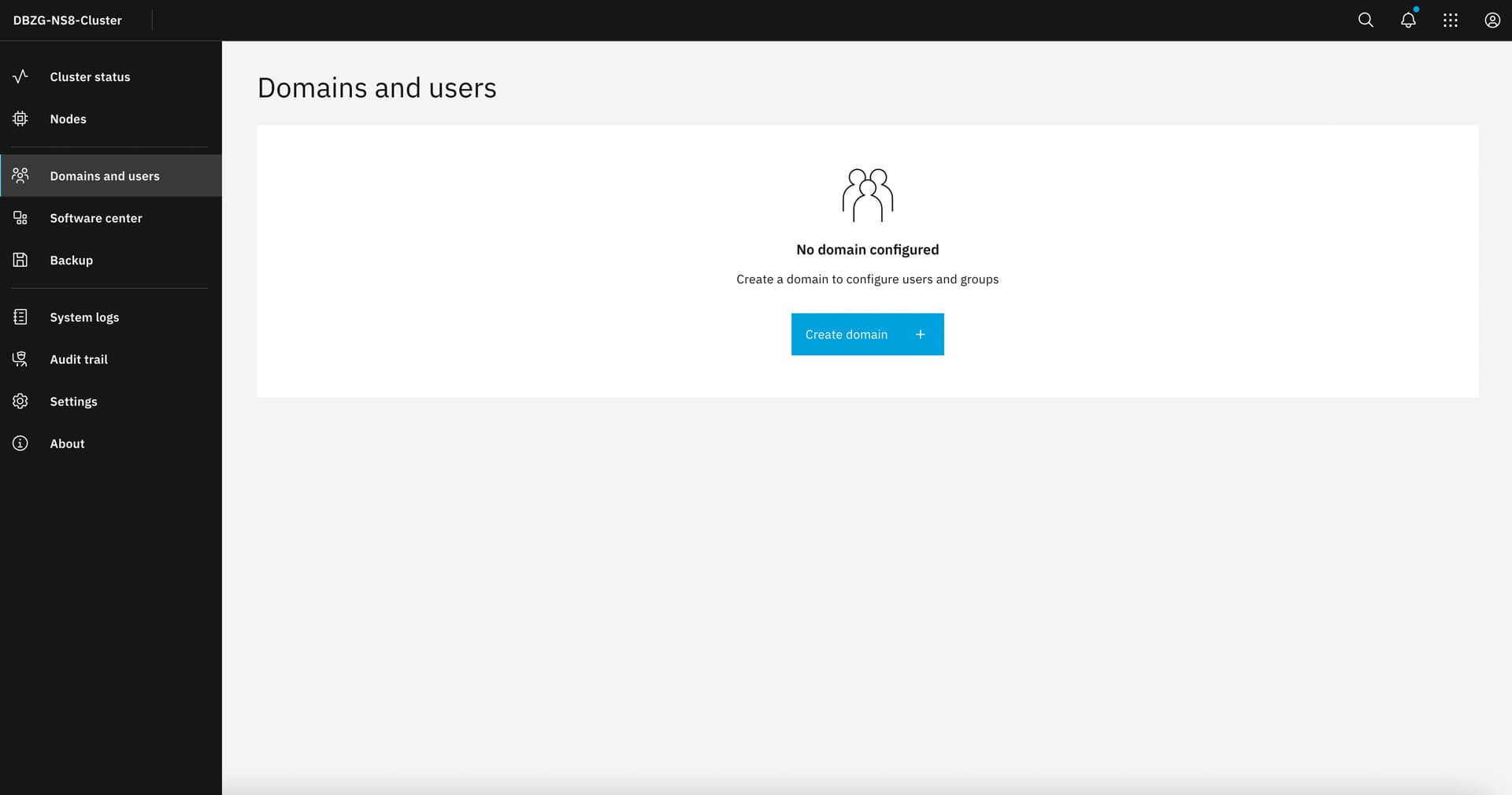
As the NS8 cluster itself (freshly installed on Debian 12 according to instructions) shows no AD Domain:
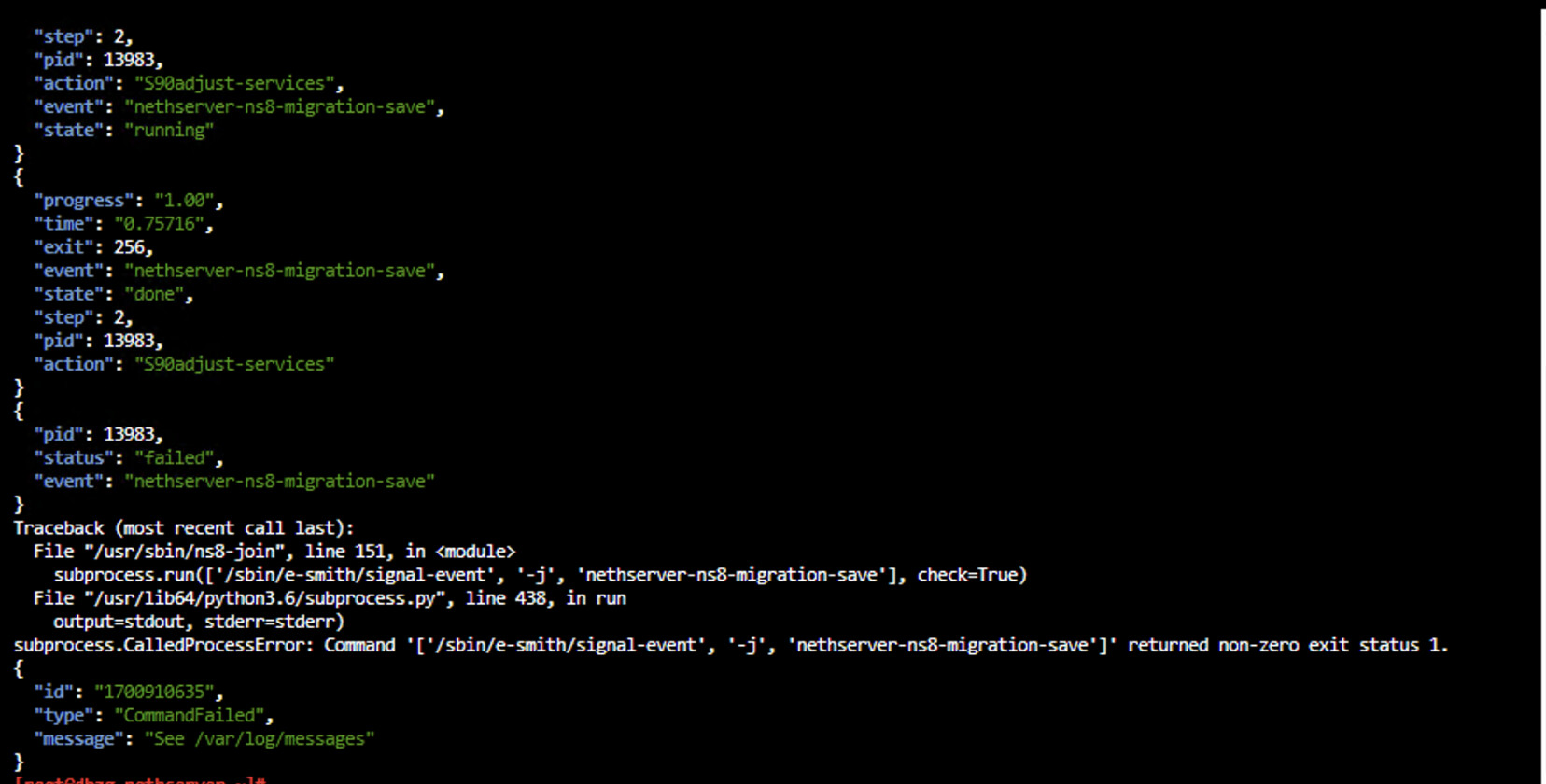
Output of the error from the console line:
[root@dbzg-nethserver ~]# echo '{"action":"login","Host":"dbzg-ns8.domainname.com","User":"admin","Password":"XXXXX","TLSVerify":"disabled"}' | /usr/bin/setsid /usr/bin/sudo /usr/libexec/nethserver/api/nethserver-ns8-migration/connection/update | jq
{
"steps": 2,
"pid": 7249,
"args": "",
"event": "nethserver-ns8-migration-save"
}
{
"step": 1,
"pid": 7249,
"action": "S05generic_template_expand",
"event": "nethserver-ns8-migration-save",
"state": "running"
}
{
"progress": "0.50",
"time": "0.086752",
"exit": 0,
"event": "nethserver-ns8-migration-save",
"state": "done",
"step": 1,
"pid": 7249,
"action": "S05generic_template_expand"
}
{
"step": 2,
"pid": 7249,
"action": "S90adjust-services",
"event": "nethserver-ns8-migration-save",
"state": "running"
}
{
"progress": "1.00",
"time": "0.784994",
"exit": 256,
"event": "nethserver-ns8-migration-save",
"state": "done",
"step": 2,
"pid": 7249,
"action": "S90adjust-services"
}
{
"pid": 7249,
"status": "failed",
"event": "nethserver-ns8-migration-save"
}
Traceback (most recent call last):
File "/usr/sbin/ns8-join", line 151, in <module>
subprocess.run(['/sbin/e-smith/signal-event', '-j', 'nethserver-ns8-migration-save'], check=True)
File "/usr/lib64/python3.6/subprocess.py", line 438, in run
output=stdout, stderr=stderr)
subprocess.CalledProcessError: Command '['/sbin/e-smith/signal-event', '-j', 'nethserver-ns8-migration-save']' returned non-zero exit status 1.
{
"id": "1700872873",
"type": "CommandFailed",
"message": "See /var/log/messages"
}
→
Note:
BAD Programming, not actually verifying the status (during a connection), but using a “locally set flag”, maybe a result of a migration attempt with faulty connections, etc.
Actually verifying would give a correct result and allow the migration. And would only take a few seconds longer…
Any suggestions on how this error can be corrected?
My 2 cents
Andy