My server is experiencing unexpected high CPU utilization. lmtp and trivial-rewrite are at the top of the list. They are running under an unrecognized user id. The CPU utilization remains high even if I disable the WAN network adapter and stop network activity. I’m running on Rocky Linux. OS is fully updated. I updated Nethserver Core this morning and have rebooted.
Restarting services stops the high network utilization for a minute or two, but then resumes.
The containers are running.
Are there specific logs that I should be looking at? There are tons of postfix/*** messages in the system logs. I’m not sure how to filter for just errors. There is significant OUTBOUND traffic that is very unusual for our small configuration.
Yes, the container users aren’t in the hosts /etc/passwd.
EDIT:
Can you identify a specific sender mail address or IP? Maybe the mail server is abused?
If you could identify a sending user you could try to change her password…
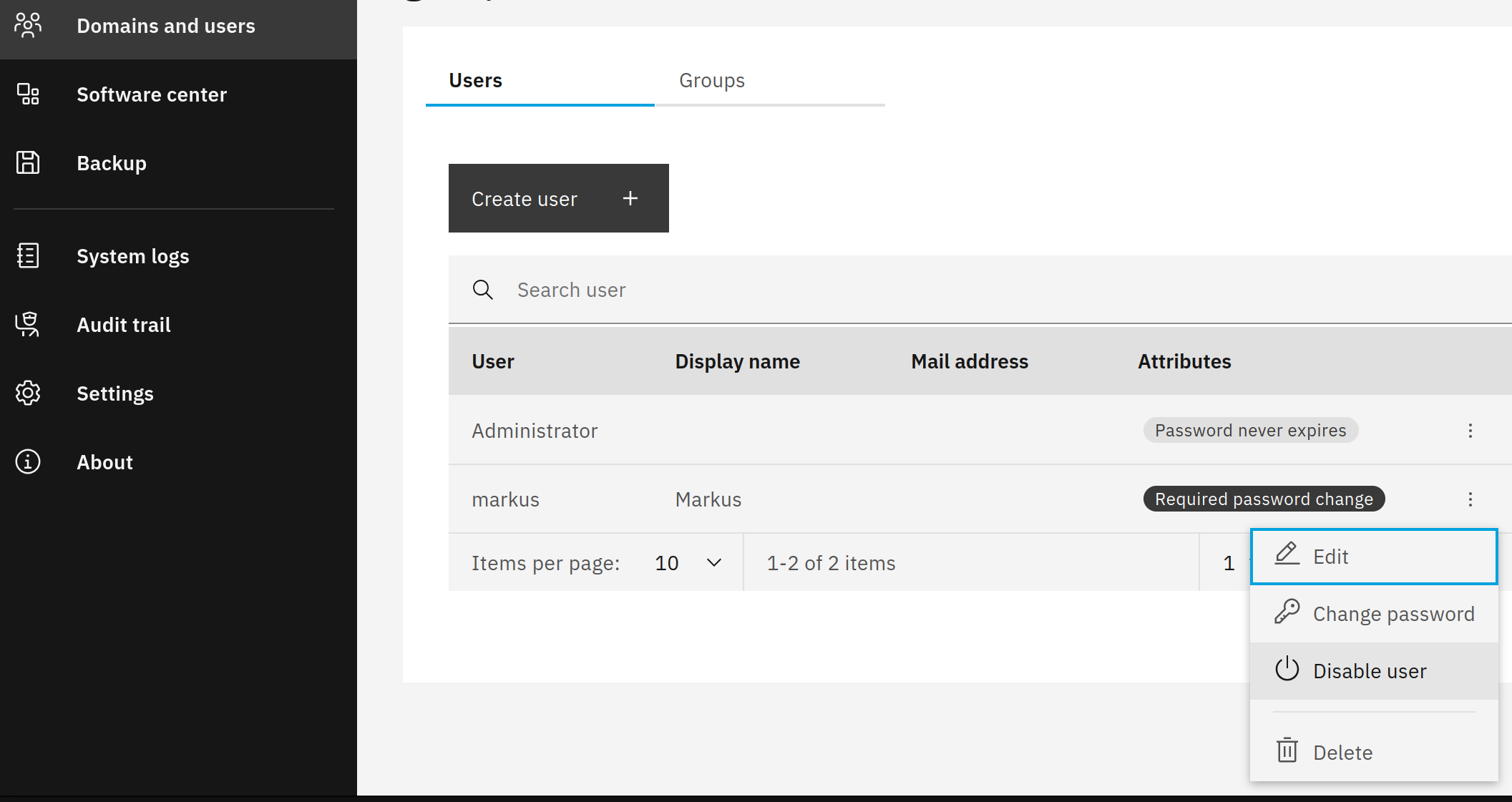
I disabled one user (at the AD DC) that might be suspect. I tried to confirm user status’ by listing users and groups in Nethserver, and I get the following error:
Traceback (most recent call last):
File "/var/lib/nethserver/cluster/actions/list-domain-users/50list_users", line 33, in <module>
users = Ldapclient.factory(**domain).list_users(extra_info=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/agent/pypkg/agent/ldapclient/ad.py", line 180, in list_users
user['must_change'] = (pwd_changed_time.timestamp() == -11644473600)
^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'list' object has no attribute 'timestamp'
There must be A LOT of messages in the queue as I cannot even get the Queue page to load. Can I view the page if the service is stopped? Is there a way to flush the queue from the command line?
I re-enabled the user in AD DC and then disabled the mail account via User mailboxes. In the brief time between enabling in AD DC and disabling via Nethserver, a bunch of messages appeared in the queue for that user. I reached out to the user and they let me know that they received thousands of “undelivered mail returned to sender” messages over the weekend.
Disabling the account and flushing the queue has returned CPU and Network utilization to reasonable levels. Thanks for your support in the matter.
I’d still like to figure out why I cannot view Domain Users. I haven’t checked that functionality for a long time, so I don’t know how long it has been broken. I did upgrade Core (and other apps) this morning to try to resolve the initial issue, so maybe the problem started then?