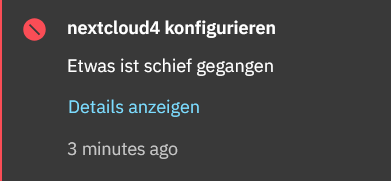
on a test instance of NS8, today I uninstalled my nextcloud instance, and later on added a new one. However, configuration of the newly installed application fails, and I am no longer able to install another nextcloud instance. I tried over again several times, but configuration always fails.
Under settings I just copied what was used in the previously deleted nextcloud instance, so the settings should be correct. The hostname points to a CNAME entry that resolves to the IP of the NS8 host, I manually gave an admin password, and use my internal ldap user domain.
Underlying rocky linux has all updates installed, also the NS8 system has all updates applied successfully.
This command runs without error when executed within the runagent -m nextcloud7 environment. However, it shows no output, the directory is empty.
Executing ls -ld in the same command shows
drwxr-x—. 2 root root 4096 Nov 1 21:12 /docker-entrypoint-initdb.d/
I don’t know whether these are the correct permissions.
Checking systemctl --user status nextcloud-db shows that this service is failed. This is what I expected, because the failed state for nextcloud-db service is also shown in the NS8 UI.
Something seems to be pretty wrong here, and I cannot explain why. All I did was to install NS8 on a fresh Rocky Linux installation a few months ago and installed some apps including nextcloud. At that time, everything was working. Now I switched the machine back on, updated everything (at that point the original nextcloud install was still working), then removed nextcloud and tried to re-install it. Since then, it is failing. I do not see anything that could/should have caused this issue.
The VM has 6GB RAM and 20GB hard disk (root), 100G hard disk (/home), with the root disk having 17G available, the /home disk having 85G available, and 1.7G free RAM, 1.8G buffer, no swap used. So it does not seem to be a resource problem.
When moving /home to a second disk, I followed the tutorial here: Disk usage — NS8 documentation
While you gave a load of detail on the vm-disk sizes used on your VM, but maybe the most important of all:
Are you running on rotating disks or SSD / NVMe ?
I notice that RAM allocation is very low, 6 MB. 8 works, more is better. But 6 is a little low if slow hardware…
After all, Nextcloud, as database based project, can use quite some RAM. As it’s not running the RAM usage may be a bit “off” so to say.
I know this is a test environment, but as a test, the results are only usable / valid, if it halfway represents reality…
But hard disks, or SSDs?
A SSD is required according to the latest docs (“40GB Solid-state drive”, see link below), and it should be 40 GB (but that’s including /home, which you removed from the equation).
good point. I double-checked and both virtual disks are allocated on an SSD. That should be fine.
I will try later with 8GB RAM to see whether this has any impact.
Still fails with 8GB RAM assigned to the VM.
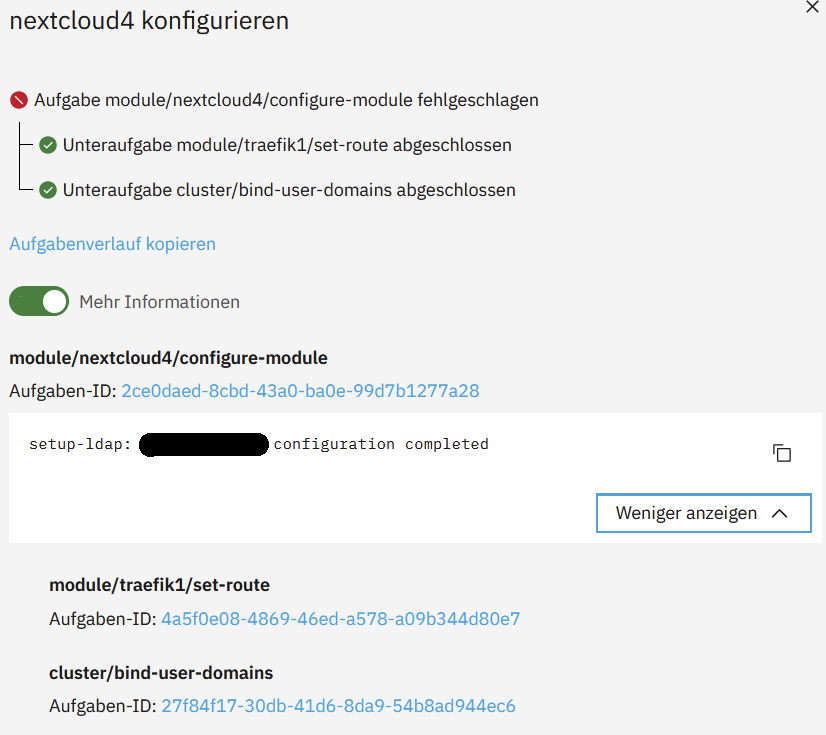
Error message from UI (I replaced the domain name with domain.com):
_acontrol_task request attempt failed (WS reached EOF while waiting for module/traefik1/task/9ad4a743-42b9-4199-a4fe-bffc92c2d50c). Retrying…
Created symlink /home/nextcloud8/.config/systemd/user/default.target.wants/nextcloud.service → /home/nextcloud8/.config/systemd/user/nextcloud.service.
Created symlink /home/nextcloud8/.config/systemd/user/default.target.wants/nextcloud-redis.service → /home/nextcloud8/.config/systemd/user/nextcloud-redis.service.
Created symlink /home/nextcloud8/.config/systemd/user/default.target.wants/nextcloud-db.service → /home/nextcloud8/.config/systemd/user/nextcloud-db.service.
Created symlink /home/nextcloud8/.config/systemd/user/default.target.wants/nextcloud-app.service → /home/nextcloud8/.config/systemd/user/nextcloud-app.service.
Created symlink /home/nextcloud8/.config/systemd/user/default.target.wants/nextcloud-nginx.service → /home/nextcloud8/.config/systemd/user/nextcloud-nginx.service.
<4>agent.ldapproxy: domain ns8test.domain.com should not be used by nextcloud8. Invoke agent.bind_user_domains([“ns8test.domain.com”]) to fix this warning.
<4>agent.ldapproxy: domain domain.com should not be used by nextcloud8. Invoke agent.bind_user_domains([“domain.com”]) to fix this warning.
setup-ldap: domain.com configuration completed