pagaille
July 22, 2025, 11:40am
21
# /sbin/e-smith/config show sssd
sssd=service
AdDns=
DiscoverDcType=dns
LdapURI=ldap://127.0.0.1
Provider=ldap
Realm=
ShellOverrideStatus=disabled
Workgroup=
status=enabled
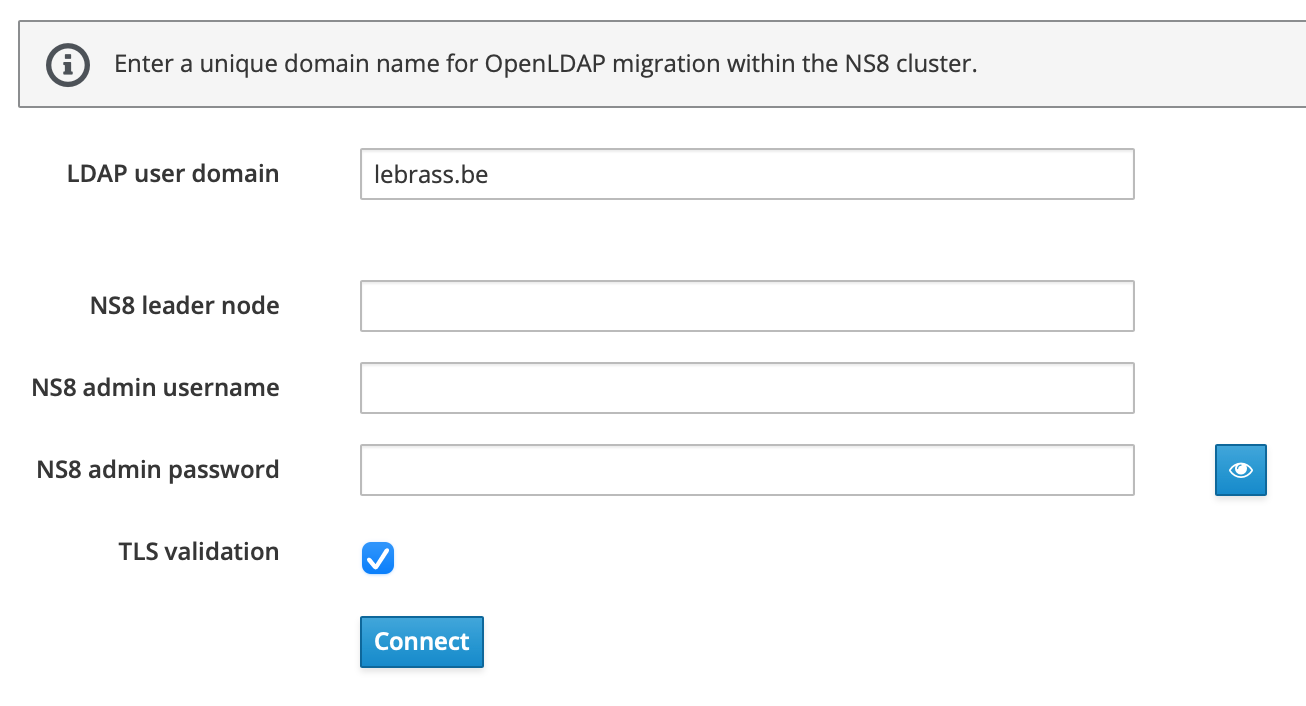
$USER_DOMAIN is not set either.
There is an alalogue conversation here : Error connecting to NS8: ns8-join: error: the following arguments are required: user_domain
1 Like
mrmarkuz
July 22, 2025, 1:06pm
22
Is it really recreated or does it still contain the data?
Are you sure it’s a samba DC because the screenshot here looks like OpenLDAP.
If it’s OpenLDAP then it should have been possible to set the new domain name during migration, see Release notes — NS8 documentation
Does it help to just set it on the NS7 to make the “finish migration” button work?
config setprop sssd Realm domain.tld
pagaille
July 22, 2025, 2:54pm
23
My bad. For me DC <> AD (= Samba) - but yes that’s a simple openldap. I don’t use Samba so not needing AD (nor DC thus ^^).
Not sure I understand that directory.nh thing
Yes.
Just tried to set the Realm : the script stalls, no error message in the logs.
mrmarkuz
July 22, 2025, 3:00pm
24
Did you use the current version of the migration tool?
[root@neth ~]# rpm -qa nethserver-ns8-migration
nethserver-ns8-migration-1.3.3-1.ns7.x86_64
mrmarkuz
July 22, 2025, 3:10pm
26
pagaille
July 22, 2025, 3:12pm
27
ne-ver saw that screen. Everything is up to date. What should trigger it ?
EDIT
I refreshed the page, clicked sync again just to see what would happen and it is still turning around, nothing happens.
mrmarkuz
July 22, 2025, 3:23pm
28
Maybe it’s possible to interrupt the process by a reboot and set the realm to directory.nh and try again?
pagaille:
What should trigger it ?
On the NS7 the slapd config needs to exist, to check:
ls /etc/e-smith/db/configuration/defaults/slapd/type
pagaille
July 22, 2025, 3:24pm
29
Positive :
# ls /etc/e-smith/db/configuration/defaults/slapd/type
/etc/e-smith/db/configuration/defaults/slapd/type
Just tried to reboot, hang on
pagaille
July 22, 2025, 3:27pm
30
rebooting the ns8 as well
# echo '{"app":"nethserver-nextcloud","action":"sync"}' | /usr/bin/setsid /usr/bin/sudo /usr/libexec/nethserver/api/nethserver-ns8-migration/migration/update | jq
**{**
**"progress"****:** "0.00"**,**
**"time"****:** "0.0"**,**
**"exit"****:** 0**,**
**"event"****:** "migration-sync"**,**
**"state"****:** "running"**,**
**"step"****:** 0**,**
**"pid"****:** 0**,**
**"action"****:** ""
**}**
rsync: failed to connect to 10.5.4.1 (10.5.4.1): Connection refused (111)
rsync error: error in socket IO (code 10) at clientserver.c(126) [sender=3.1.2]
1 Like
pagaille
July 22, 2025, 8:24pm
31
Starting over.
Actually the ldap parameter is there (but not at the same place as your screen cap)
This time there was no error related to the USER_DOMAIN but still the event migration-sync fired by the Finish migration button is neverending and the system is idle.
Basically I’m coming to the same conclusion as you, even with a volume mounted with the selinux context . I’ll investigate further tomorrow.
1 Like
pagaille
July 23, 2025, 7:04am
32
I did some experiments and I believe that the main concern (rsync: [generator] chown “/var/www/html/.” failed: Operation not permitted (1) when finishing the migration or starting the app) is due to the root of the bind-mount not owned by www-data:www-data - which is translated outside the container to make things worse.
Currently I don’t see a practical and robust way of making this setup work in production, do you agree ? So the only options are
eat the pill and stay on slow storage (can’t afford To of NVMe)
migrate normally and then move the storage to an external one (smb), loosing the versioning and the existing shares. Not sexy.
What do you think ?
mrmarkuz
July 23, 2025, 7:16am
33
I noticed you setup selinux like that:
But maybe it didn’t work correctly. Did you try to disable selinux for the container?
mrmarkuz:
runagent -m nextcloud1 systemctl --user edit --full nextcloud-app
--security-opt label=disable needs to be added to the ExecStart=/usr/bin/podman run line:
ExecStart=/usr/bin/podman run --security-opt label=disable --conmon-pidfile ...
pagaille
July 23, 2025, 7:18am
34
yes, tried as well. The container starts now (after chown the root of the bind-mount), even if I land on a bad gateway page but that’s another story.
I believe we may make it work but my main concern is : will it be robust enough on the long run… And survive updates…
mrmarkuz
July 23, 2025, 7:22am
35
If you edit the systemd service file like explained in following post, it will survive updates but it’s lost after a restore.
Unfortunately there’s no volume in collabora so to make the changes persistent, we need to add a volume. This way this customization will survive updates but the coolwsd.xml is not included in backup so better to keep a copy of coolwsd.xml somewhere, in case you need it after restore.
Enter collabora1 environment: (adapt to your collabora instance name)
runagent -m collabora1
Edit the systemd service file…
systemctl --user edit collabora
…until it looks like this:
### Editing /home/collabo…
pagaille
July 23, 2025, 7:37am
36
I stumbled upon this GitHub - containers/udica: This repository contains a tool for generating SELinux security profiles for containers but it’s clearly outside my sphere of competence
1 Like
mrmarkuz
July 23, 2025, 7:48am
37
Small letter :z defines a shared volume over more containers, capital letter :Z is for private volumes. I don’t think it helps us in this case.
It seems to try to automate creating selinux exceptions. Looks interesting.
pagaille
July 23, 2025, 8:22am
38
Got some success
This what I did :
mount the xfs drive with context=system_u:object_r:container_file_t:s0
init migration
go into the app environment and
# Fix permissions
# 1. inside the container :
grep ^nextcloud2: /etc/subuid
nextcloud2:493216:65536
# 2. fix from outside the container
chown -R 493298:493298 /mnt/nextcloudstorage # # 493216+82 = 493298 !
# EDIT : that should be 493216 + 82 -1 = 493297... but it works anyway (probably not needed)
chmod 777 /mnt/nextcloudstorage # not sure it's needed
stop rsync-nextcloudx
delete then recreate the volume bind-mounted
podman volume create \
--opt type=none \
--opt device=/mnt/nextcloudstorage \
--opt o=bind \
nextcloud-app-data
relaunch rsync-nextcloudx with --security-opt label=disable !
Launch the sync
edit systemctl --user edit --full nextcloud-app → add --security-opt label=disable
not sure I restarted rsync-nextcloudx at this step. Might be.
Finish the migration → success
1 Like
pagaille
July 26, 2025, 12:23pm
39
Did it a second time on a separate worker node. Worked flawlessly, at least the migration itself.
I discovered that chmod 777 and mounting the external drive with context=system_u:object_r:container_file_t:s0 was mandatory.
I’ll report my findings regarding the post-migration steps. I had some problems at first try that are discussed here Nextcloud error after migration from NS7 - #20 by pagaille
Thanks again @mrmarkuz for the good pointers and insight you shared with me.
1 Like
pagaille
July 26, 2025, 2:08pm
40
Good news : on the second try, the migration process was practically a breeze. The problems I encountered the first time (ie all LDAP users disabled) didn’t came back.
Thanks again @mrmarkuz !
If anybody needs help regarding this experiment feel free to ask.
1 Like