Hi all,
Thank you @Andy_Wismer but I already consulted those pages to no avail.
Those guys forgot a very important fact: the swap. It looks as they don’t have one.
So, if they extend the disk, the new extension part will be at the end of all the other partitions i.e. after the swap. Then the first partition is impossible to resize as the swap is between the first partition and the extension part.
I added 50G to the disk.
Boot the VM with gparted-AMD64 and exit to the cosole.
Start fdisk /dev/sda and delete the swap and the extended partition.
I created a 48G primary partiton, then an extended one at the end (3G), another partition (type 83) in the extended one, changed the type from Type 83 to Type 82 (swap).
Delete the 2nd partition to be able to extend the 1st one.
Write and quit fdisk.
Back to the gparted console, reboot as sda1 was never touched.
Re-entered gparted and extended sda1.
Applied and reboot.
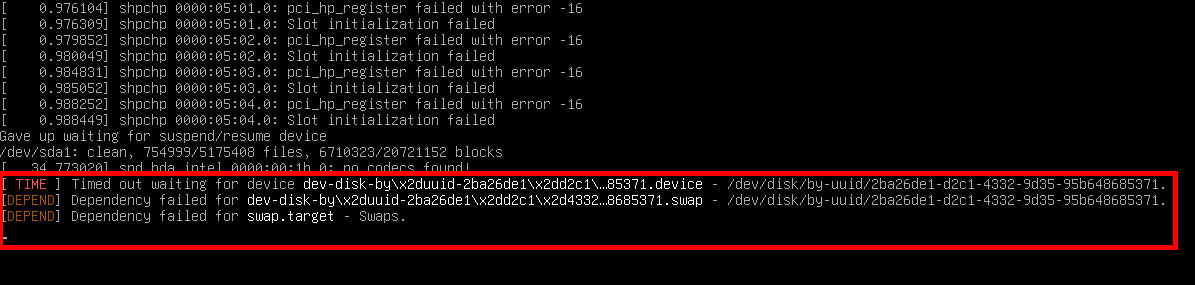
The boot complained about the swap:
But after 2-3 minutes, Debian finished the boot and offered the login page.
[root@ns8 ~]# fdisk -l
Disque /dev/sda : 82 GiB, 88046829568 octets, 171966464 secteurs
Modèle de disque : QEMU HARDDISK
Unités : secteur de 1 × 512 = 512 octets
Taille de secteur (logique / physique) : 512 octets / 512 octets
taille d'E/S (minimale / optimale) : 512 octets / 512 octets
Type d'étiquette de disque : dos
Identifiant de disque : 0x95722270
Périphérique Amorçage Début Fin Secteurs Taille Id Type
/dev/sda1 * 2048 165771263 165769216 79G 83 Linux <<<==================
/dev/sda4 165771264 171966463 6195200 3G 5 Étendue
/dev/sda5 165773312 171966463 6193152 3G 82 partition d'échange Linux / So
[root@ns8 ~]#
[root@ns8 ~]# cat /proc/partitions
major minor #blocks name
8 0 85983232 sda
8 1 82884608 sda1 <<<==================
8 4 1 sda4
8 5 3096576 sda5 <<<==================
11 0 524288 sr0
[root@ns8 ~]#
I ajusted fstab to the new UUID of sda1 and sda5 (swap). The reboot still complained but took less time to offer the login screen.
I thought I will now be able to raise the victory banner and install WordPress; but I was not able to get the admin-cluster page of NS8.
Conclusion
I managed to “solve” the problem of extending the disk but the extension generated another problem.
And to crown everything, last night, I lost one of my Proxmox RAID 1TB disk.
Computer life has some interesting surprises!
Enough, “loosing time”, I will restart from scratch, it will be faster…
Michel-André