Thought it was about time to try a full disaster recovery scenario, especially based on the bad luck I’ve had applying updates in the past. So, this is going to be a long post, mainly of a big cut/past of a screen shot.
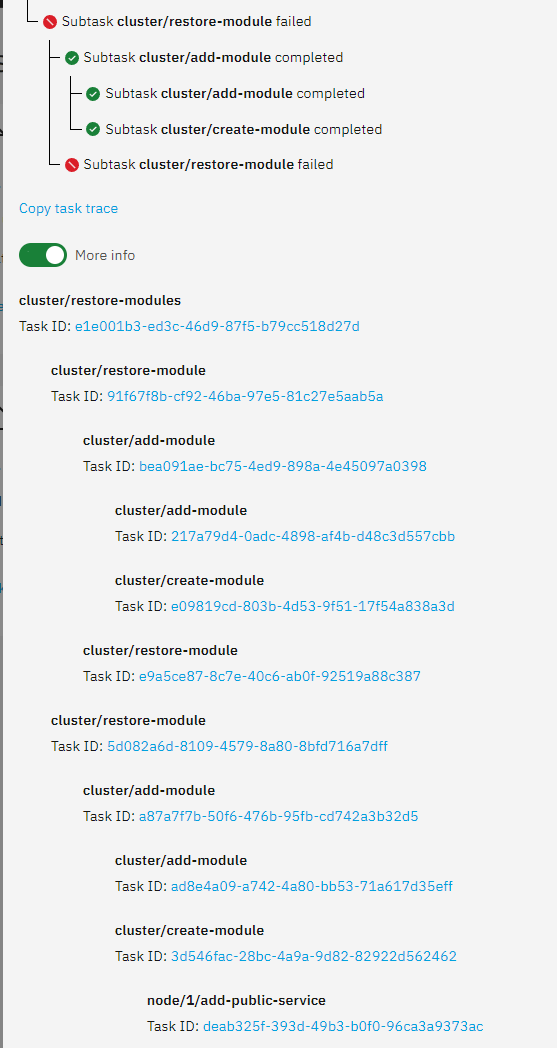
Downloaded and booted the latest Rocky image and selected the Restore Cluster and followed the instructions. Here’s the details following the “Something went wrong” message:
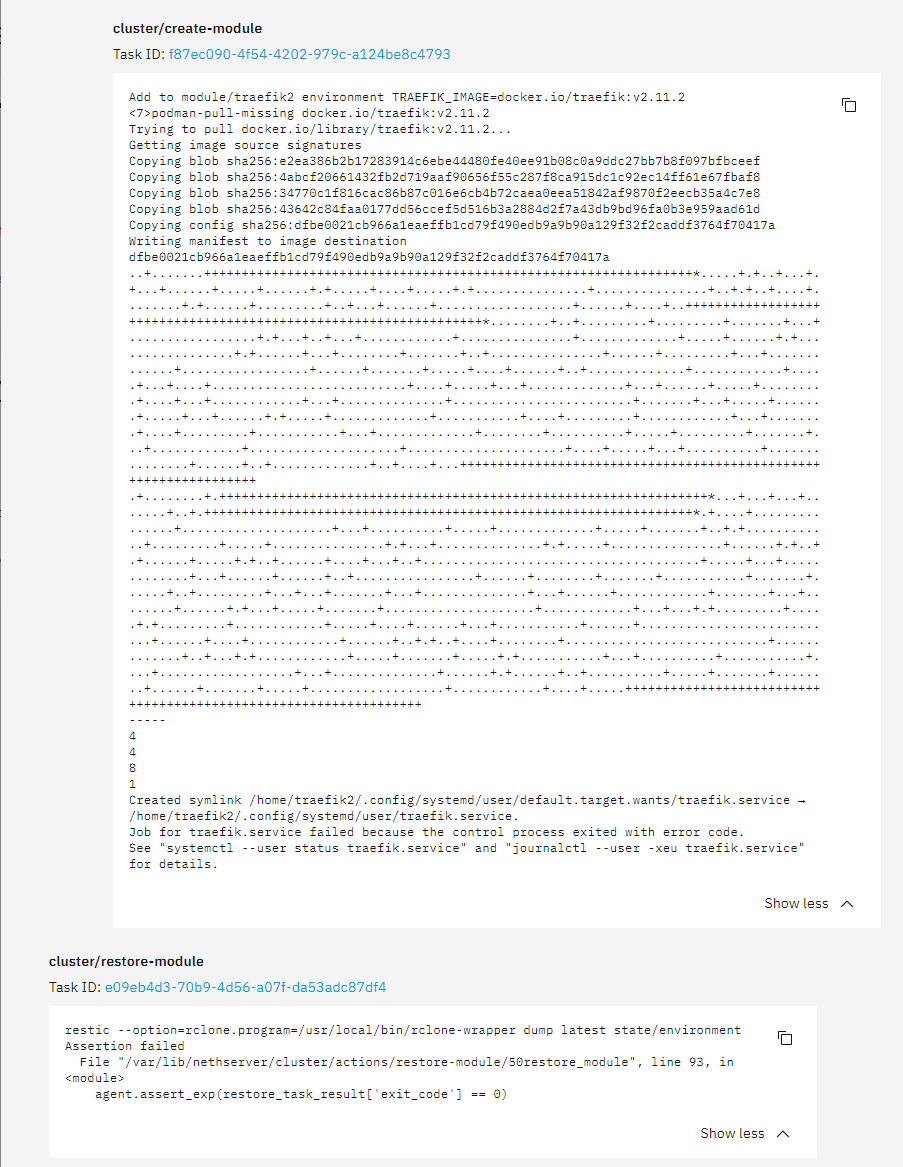
Job for traefik.service failed because the control process exited with error code.
See “systemctl --user status traefik.service” and “journalctl --user -xeu traefik.service” for details
The No Entries is the response to the journalctl command.
I’m not sure how many of these are minor issues that can be ignored (I can see at least 1, maybe 2) or which are portents of failure down the road should I continue to use this system, which I’m not going to be other than to pull information should you need it.
***** Update *****
Just noticed that one of the failures was trying to add an instance of traefik2.
I’m guessing had that worked it would be then be like loki, 2 instances both running. Is that really what was supposed to happen.
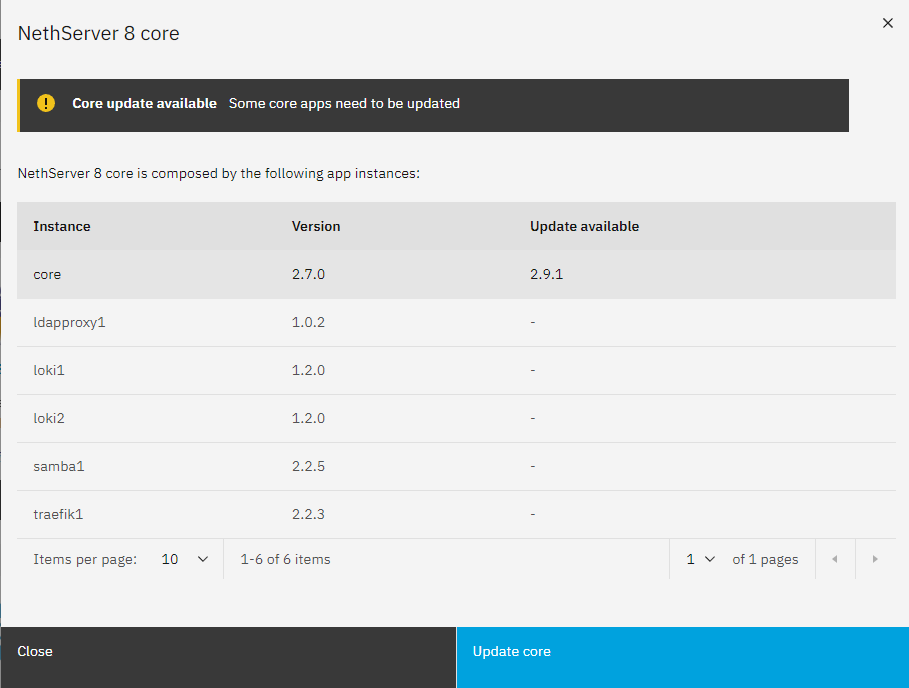
Regarding the loki and traefik issues, i had similar results. The issue is that only one of each can be present on a particular node. I ended up removing the default instances from the command line via remove-module command.
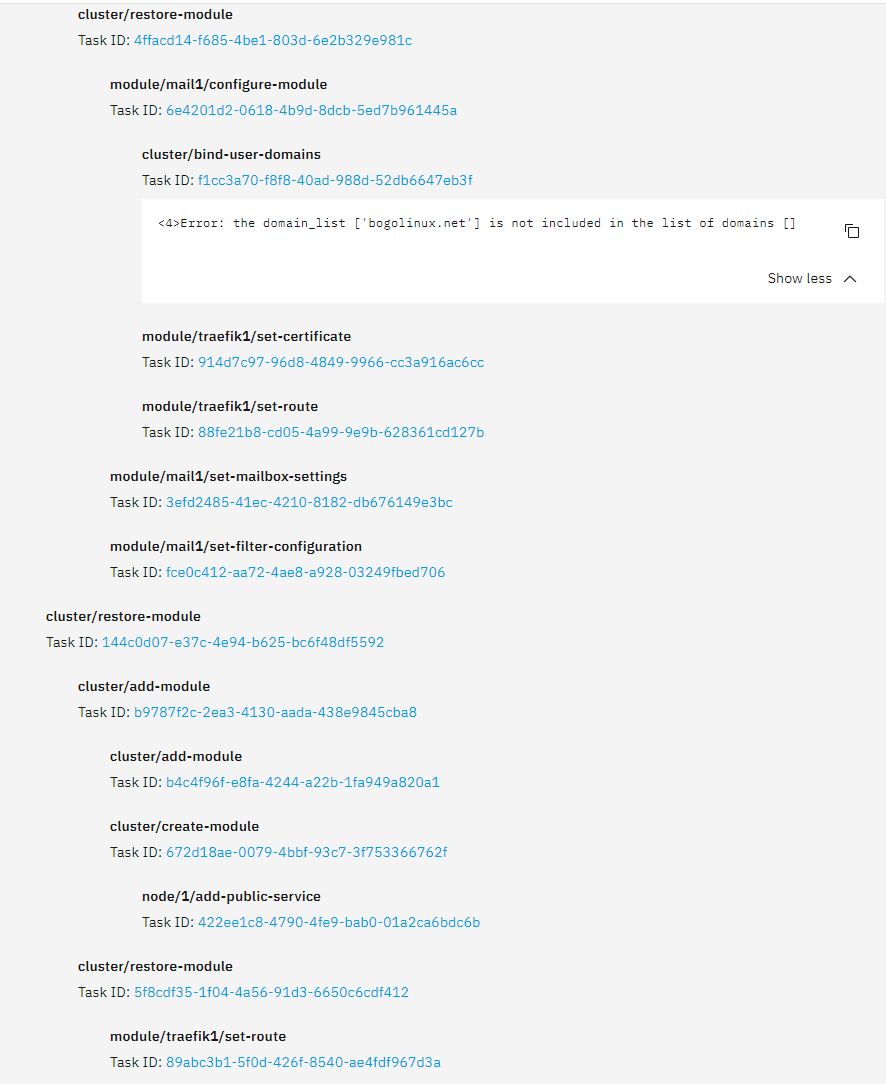
Mail encountered some non-fatal errors (related to the certificate and binding to the account provider). These can be resolved later in the app’s Settings page.
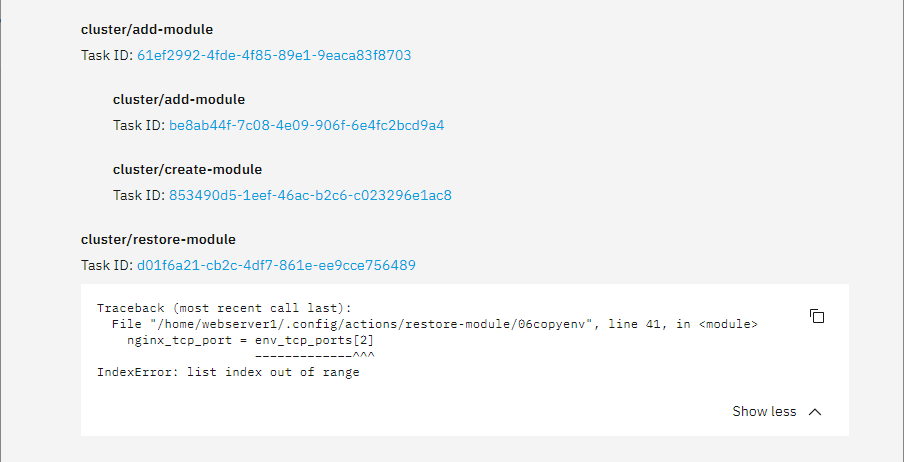
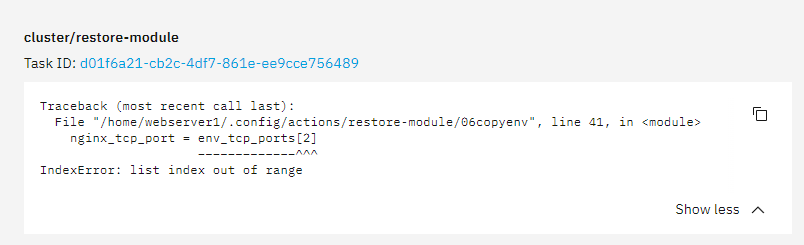
The Webserver experienced a fatal restore error (IndexError). /cc @stephdl
Traefik also failed to restore. The service startup is failing because ports 80 and 443 are already in use by the core Traefik instance. I believe Traefik should be excluded from the restore process, as certificates and routes are managed by the cluster backup. Installing a second Traefik instance is unnecessary.
On the other hand, a second instance of Loki is allowed, as documented here.
Except both instances of loki are currently running. Shouldn’t loki and traefik be treated somewhat special in that the core version should be updated with the settings from the backup, instead of trying to restore the backup.
I don’t see a 3-dot menu to remove the inactive loki. *** Ignore, I found where this is now. ***
Traceback (most recent call last):
File “/home/webserver1/.config/actions/restore-module/06copyenv”, line 41, in
nginx_tcp_port = env_tcp_ports[2]
~~~~~~~~~~~~~^^^
IndexError: list index out of range
Or were you asking for everything I took as a screen shot as text. If so, I can capture each text box separately.
And as indicated earlier, I have the full trace as well.
That restored without error and the SFTPGo settings were correctly retained. I’m guessing that it’s not possible to restore as the same instance number, as the restore creates webserver2. Not that it really matters.
I’m also guessing that I won’t be able to test this as a disaster recovery scenario until the fix is released so that the restore will pull down the updated code.
Talking of the disaster recovery, is there anything happening regarding samba not restoring correctly, which causes other issues in mail or my suggestion for loki and traefik to not attempt a restore, but update the core version (or maybe delete the core version before a restore).