NethServer Version: latest
Module: ALL!
So I installed an NS8 (not my first), for a friend SOHO, using the pre-made image (Rocky), just for mail services, nothing else (yet). Set a single email, connected it to a few mail clients and told them, they can move PROGRESSIVELY older mail (for archiving) to that account.
They did that for a day or so, then they reported me, that it doesn’t seem to sync with the server (their mail clients).
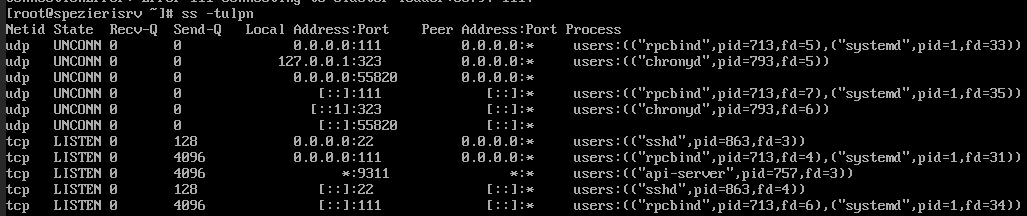
So I went to the web interface only to find it was NOT available!
Then I rebooted NS8 (it is a VM) AND NOW IT DOES NOT BOOT NS8, but only Linux (the console prompt says “Rocky Linux 9.5 (Blue Onyx)” but NOT the cluster admin URLs!!!
HELP! What can I do!? I need to at least access the mail that was already transfered to their server!
What happened? Could it be overwhelmed by some sudden “attack” of mailbox transfers? (their emails are more than 100GB total… they may have tried to move folders NOT progressively after some point)
How could this destroy NS8 itself???
EDIT:
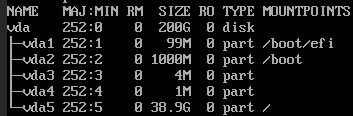
Note that the server’s qcow image has grown to 37GB and lives inside an array that has plenty of more space to grow.
Is it possible it cannot grow more for some reason and is full or something?
EDIT #2:
Even network is not up. I cannot ping the server or the server ping anything else.
I used NS7 for years and NS8 almost since the beginning. I have stable NS8 installs, I never expected a server would crash in a day and NOT boot NS8 at all…
At this point I am looking even at just using this qcow as source image to setup a fresh NS8 and get (somehow) the mailbox from the “old” one (where “old” means a few days ago…). I will try anything you can propose! Just help please…