NethServer Version: 8Module: your_module
Hi everyone,
I’m trying to setup a local backup when the destination is a disk of a worker (remote) node. Backup works but the files go to the disk 1 of the worker, which is small (I think is a system disk). So I want to tell Nethserver to use disk 3 which is the largest partition. Here is my node layout:
As you can see there is a disk 4 which I mounted with podman (refer to the Backup guide) but it always go to the disk 1.
How can I specify the destination disk?
mrmarkuz
July 24, 2025, 3:11pm
2
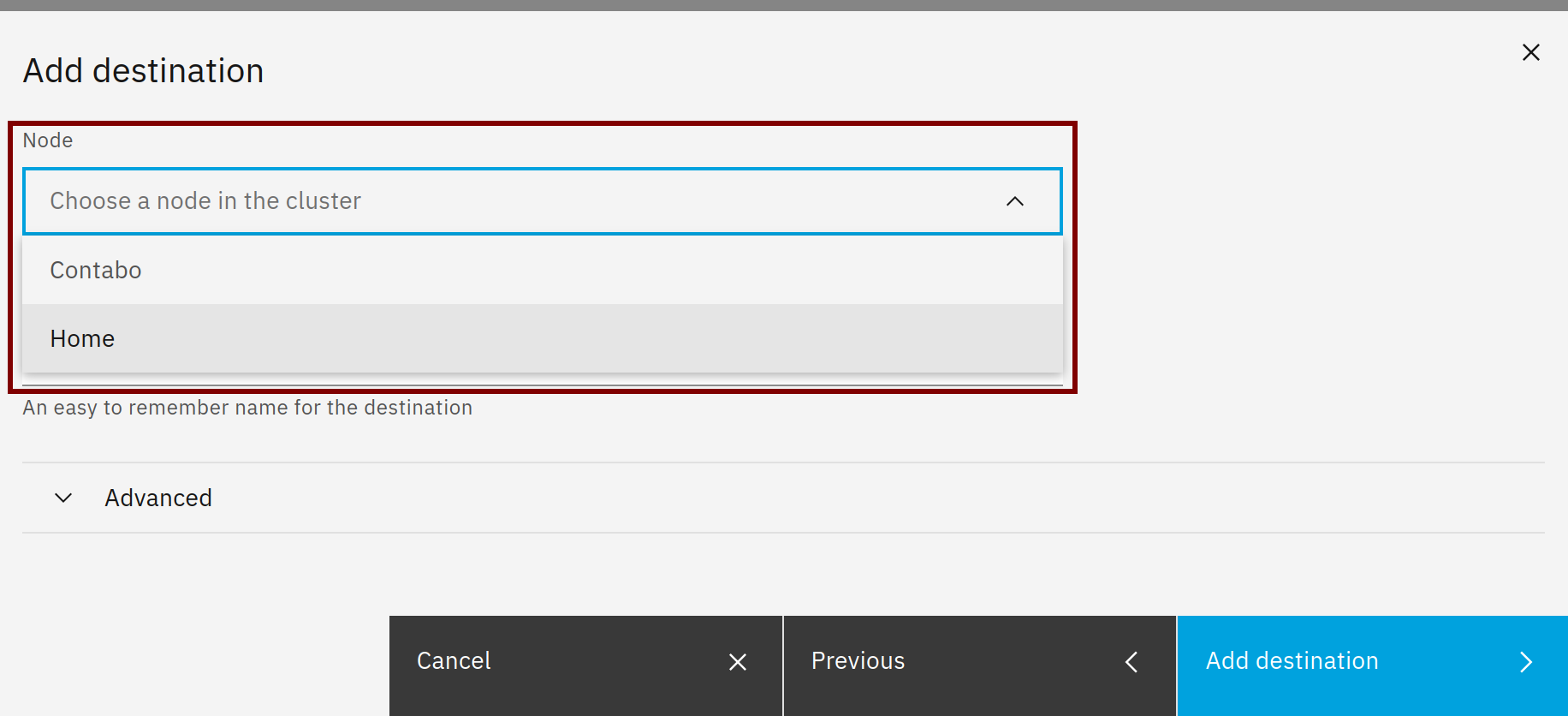
It’s done in point 3 in Backup and restore — NS8 documentation
It seems you specified the volume name BACKUP_NOCI instead of volume00 so following command should tell the node to use the BACKUP_NOCI volume:
echo BACKUP_VOLUME=BACKUP_NOCI > /var/lib/nethserver/node/state/rclone-webdav.env
Hi Markus,
Thanks for the reply. I’ve used this commands:
podman volume create --label org.nethserver.role=backup -opt=device=/dev/mapper/rl-home --opt=o=noatime BACKUP_NOCI
echo BACKUP_VOLUME=BACKUP_NOCI > /var/lib/nethserver/node/state/rclone-webdav.env
And restart the rclone-webdav service
mrmarkuz
July 24, 2025, 3:39pm
4
Disk 3 and Disk 4 are the same device (/dev/mapper/rl-home) and same size, is it a software RAID?
The backup mount point is just on disk 4.
Maybe it helps to use the disk id instead of /dev/mapper/rl-home ?
/dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_drive-scsi0
Ok thanks.
Task module/loki1/run-backup run failed: {'output': '', 'error': 'time="2025-07-25T14:55:04+02:00" level=error msg="Refreshing container f3cfb03f7bd9ffad2fb2b97588d70bcb5e55062c44c1a2f22586d69b6b4b7a23: acquiring lock 0 for container f3cfb03f7bd9ffad2fb2b97588d70bcb5e55062c44c1a2f22586d69b6b4b7a23: file exists"\ntime="2025-07-25T14:55:04+02:00" level=warning msg="Found incomplete layer \\"4c0f93f21f0a343a3f19f96e4364d477c04e526cb9424c61ff3eb9e8b3fc22b0\\", deleting it"\npanic: runtime error: invalid memory address or nil pointer dereference\n[signal SIGSEGV: segmentation violation code=0x1 addr=0x100 pc=0x55f758cbf7f7]\n\ngoroutine 1 gp=0xc0000061c0 m=3 mp=0xc000088e08 [running]:\npanic({0x55f759cc2f60?, 0x55f75ad48050?})\n\t/usr/lib/golang/src/runtime/panic.go:804 +0x168 fp=0xc000559d30 sp=0xc000559c80 pc=0x55f7582b0508\nruntime.panicmem(...)\n\t/usr/lib/golang/src/runtime/panic.go:262\nruntime.sigpanic()\n\t/usr/lib/golang/src/runtime/signal_unix.go:900 +0x359 fp=0xc000559d90 sp=0xc000559d30
(truncated)
1 Like
mrmarkuz
July 25, 2025, 1:54pm
6
I retested the local backup and it worked to backup apps to another node than the leader node. Do you use Rocky/RHEL?
Did you choose the right node in the local backup destination?
The steps explained in the docs need to be executed on the node that has the local disk attached, in your case node 4.
As an alternative you could install minio which also supports backing up to a local disk.
Still I’m wondering about disk 3 and disk 4 which share the same size and disk usage but have different mount points.
Francesco_Verna:
I mounted it by its UUID
I didn’t test using the UUID, I used the disk id like explained in the docs.
podman volume create
--label org.nethserver.role=backup
--opt=device=/dev/disk/by-id/scsi-0QEMU_QEMU_HARDDISK_drive-scsi1-part1
--opt=o=noatime
backup00
mrmarkuz:
BACKUP_NOCI
Maybe the underscore is a problem?