Hi,
AlertManager keeps yelling that my swap is filling up :
[1] Firing
Labels
alertname = swap_full
instance = 10.5.4.6:9100
job = providers
node = 6
severity = warning
Annotations
description = Swap is filling up (>80%) VALUE = 81.60469667318982 LABELS = map[instance:10.5.4.6:9100 job:providers node:6]
summary = Host swap is filling up (instance 10.5.4.6:9100)
The problem is that this VM has plenty of ram available (7 GiB, 1 GiB swap just in case, 2Gib really used, 5Gib used by buffers and caches)
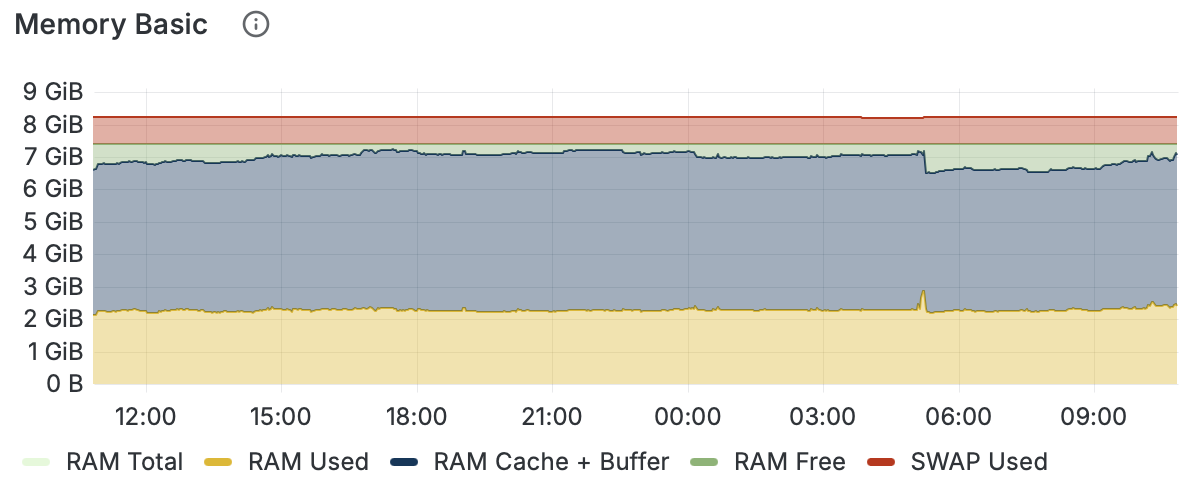
but Collabora get swapped no matter I set the swapiness.
# sudo smem -rs swap
PID User Command Swap USS PSS RSS
465061 363144 /usr/bin/coolforkit-ns --sy 364632 160 3637 37980
465068 363144 /usr/bin/coolforkit-ns --sy 364476 164 3659 38136
465066 363144 /usr/bin/coolforkit-ns --sy 364476 164 3659 38136
465067 363144 /usr/bin/coolforkit-ns --sy 364472 164 3660 38140
484548 363144 /usr/bin/coolforkit-ns --sy 364452 164 3663 38160
484546 363144 /usr/bin/coolforkit-ns --sy 364452 164 3663 38160
464991 363144 /usr/bin/coolforkit-ns --sy 364124 164 3814 38444
484544 363144 /usr/bin/coolforkit-ns --sy 363728 512 3325 30356
1183484 363144 /usr/bin/coolforkit-ns --sy 358072 6512 12957 53376
1180889 363144 /usr/bin/coolforkit-ns --sy 357928 6684 13121 53520
1180876 363144 /usr/bin/coolforkit-ns --sy 308948 155184 161968 200084
2165 100099 /usr/bin/redis-server unixs 152100 55256 55797 57720
It seems to be a usual “problem” or kernel behaviour . In my case there is virtually almost no swapping occurring and I believe there is nothing wrong.
Las 2 days :
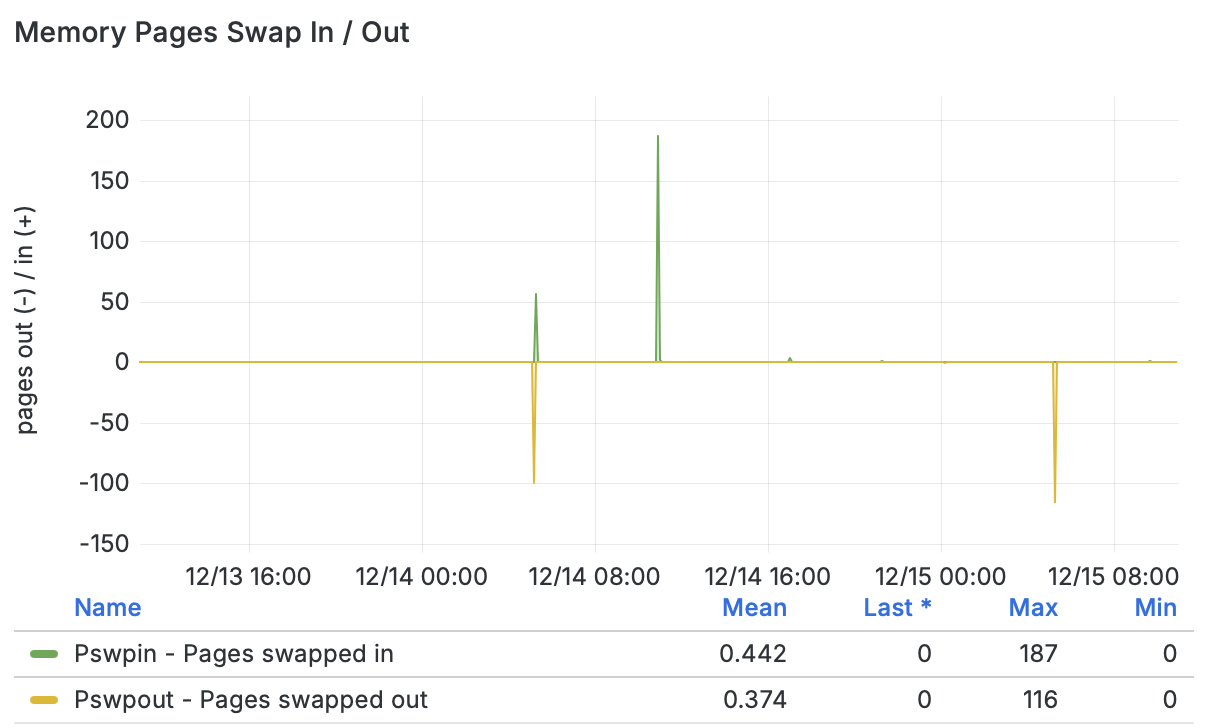
Therefore I guess I could disable that rule ? How would I do that ?
Any other advice ?
Thanks !