Then pick you choice out of the many languages to be recognized and install them (English is installed by default): “yum search all tesseract”
and install the requered language(s) e.g. yum install tesseract-langpack-fra
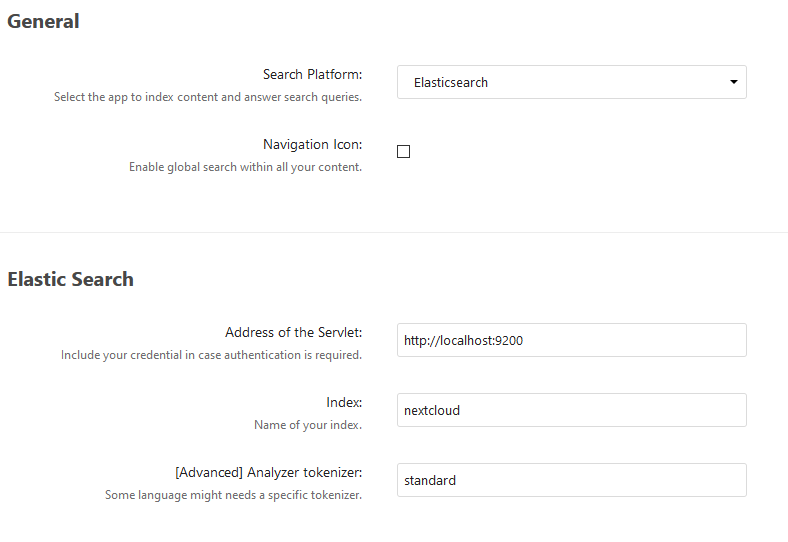
Install the full text search OCR app in nextcloud, go to settings → search and set your installed languages (watch the language abbreviation e.g. eng,fra,deu) and enable OCR.
Just not sure the interval when elasticsearch re-indexes, maybe this is related to the cronjob?
Strangely, the yum search all comes up with many language packs, but none mention English. Even did a grep in case I was inadvertently looking past it. ?? OK, there is -enm for Middle English, but I’m not going to be working with Chaucer.
I do not have the remi-phpscl module installed my directory is /opt/rh/rh-php71 and not /opt/rh/rh-php56/ do i need to install the remi-phpscl module to run the index command correctly?
The remi set comes from the php-scl module that can be installed seperately. Nextcloud takes care of a different scl version of php. Yes, that is confusing.
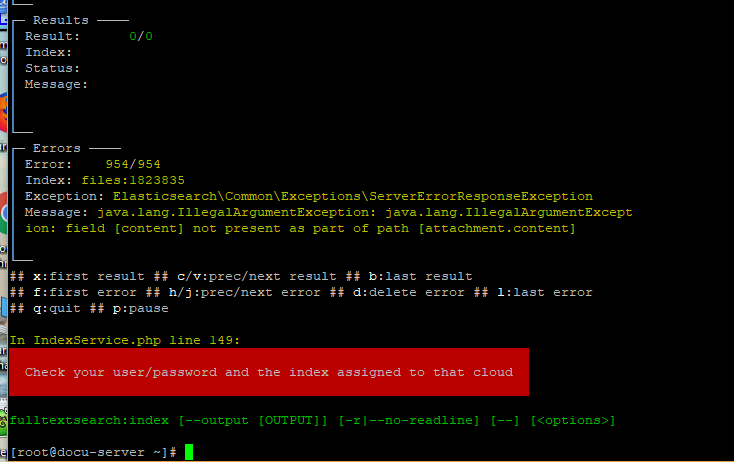
Hello I had to reinstall Elasticsearch now when I run sudo -u apache /opt/rh/rh-php71/root/usr/bin/php -d memory_limit=512M /usr/share/nextcloud/occ fulltextsearch:index I get the following error.
Still getting the error PHP Fatal error: Allowed memory size of 536870912 bytes exhausted (tried to allocate 57555268 bytes) in /usr/share/nextcloud/apps/files_fulltextsearch/lib/Service/FilesService.php on line 964" when trying to index files using nextcloud and elastic search I have read here https://help.nextcloud.com/t/allowed-memory-size-of-xxx-bytes-exhausted/39371/10 /etc/php/cli/php.ini should contain -1 for memory limit, how do I find this file in a Nethserver installation and how do I change the the setting.
On the current php version used by NethServer for Nextcloud, the global php.ini file would be /etc/opt/rh/rh-php73/php.ini, where memory_limit defaults to 128M.
But the PHP error says it exhausted 512MiB. I guess those 512MiB are the ones set in a custom rule at /etc/opt/rh/rh-php73/php-fpm.d/000-nextcloud.conf:
The latter file comes from nethserver-nextcloud package and can be overridden by updates.
There is no esmith db prop for it that I recall, so one option could be to drop a fragment file. Untested but think something along the lines of this shall work:
The file is set as a configuration file so you can edit and adjust the value or add others. During the upgrade this file will not be modified by the rpm one
I made the changes as suggested now I’m getting the following " Job for rh-php73-php-fpm.service failed because the control process exited with error code. See “systemctl status rh-php73-php-fpm.service” and “journalctl -xe” when I run the command “systemctl restart rh-php73-php-fpm”
As Stephane said there’s no need for a custom template. If you created the template file, it can be removed.
You can edit the file /etc/opt/rh/rh-php73/php-fpm.d/000-nextcloud.conf directly, tweaking the value of php_admin_value[memory_limit].
Since the update, I’ve noticed that Elasticsearch in Nextcloud doesn’t index the contents of eg. PDFs. Most PDFs are from Adobe Pro in this case, with OCR already “prepared”, not just containing a scanned image of text. There are those too, but a PDF containing text should be indexed…
A search for documents only shows results, if the search is part of the filename. No results are shown for contents…
It doesn’t even index simple textfiles (.txt)…
NethServer and Nextcloud including all installed Apps are top up to date.

{kind=link}